What Is Mega-ASR?
Mega-ASR is one of the best AI Speech Recognition Models tools for ML engineers and speech platform teams. Built by the xzf-thu research team, Mega-ASR is a foundation ASR model that targets in-the-wild transcription by training on 2.6M samples across 7 atomic acoustic conditions and 54 compound scenarios, so it stays useful when noise, echo, far-field speech, obstruction, distortion, or transmission dropout break standard ASR.
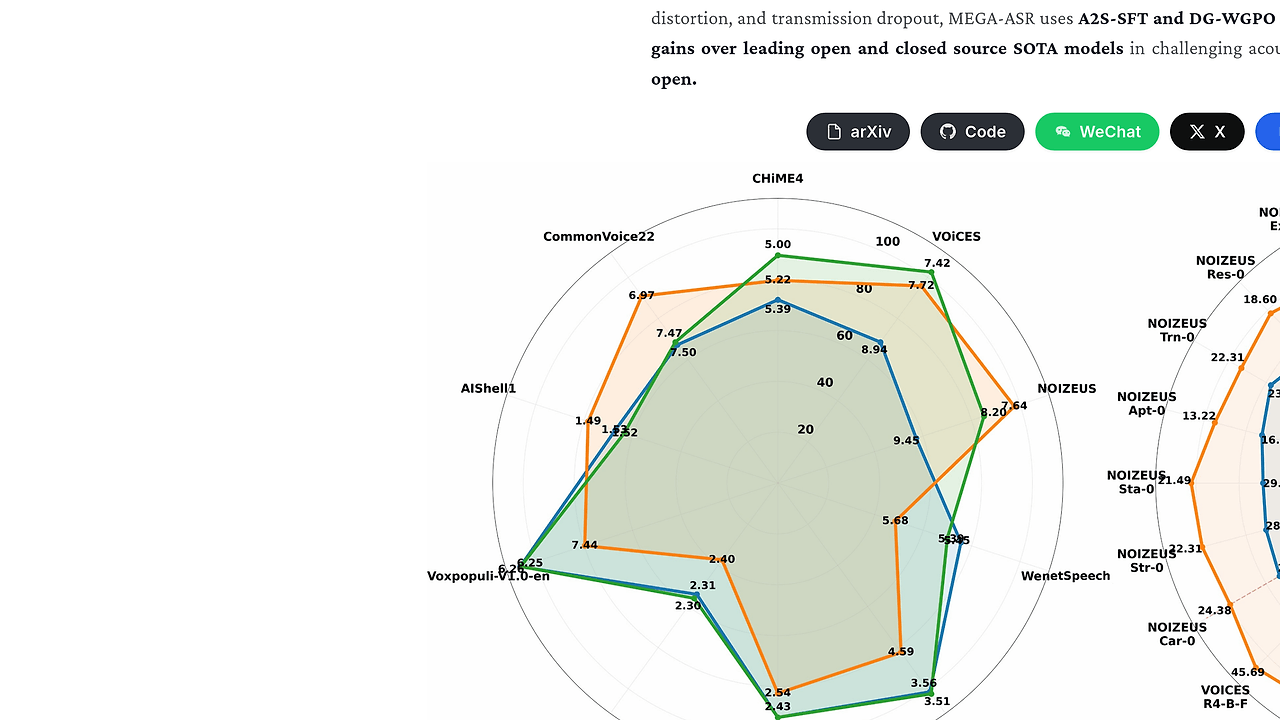
The repo positions Mega-ASR as a hard-case model, not a clean-lab benchmark toy. It claims up to nearly 30% gains over leading open- and closed-source SOTA models in the toughest acoustic settings, and the sample table on the page shows a noisy clip where Mega-ASR cuts WER to 47.1 while several baselines stay above 85.
Quick Overview
| Attribute | Details |
|---|---|
| Type | AI Speech Recognition Models |
| Best For | ML engineers and speech platform teams |
| Language/Stack | Python, PyTorch, Hugging Face |
| License | N/A — not stated in the page text |
| GitHub Stars | N/A as of May 2026 |
| Pricing | Open-Source |
| Last Release | N/A — not stated in the page text |
Who Should Use Mega-ASR?
- Speech infrastructure teams shipping call transcription, meeting notes, or customer support tooling that must survive noisy microphones, codec artifacts, and room echo.
- ML engineers who need a stronger baseline than clean-audio ASR when evaluating models on field recordings, car audio, phone calls, or mixed-source datasets.
- Applied researchers benchmarking robustness across acoustic degradations and needing a model trained on structured scenario mixtures instead of ad hoc augmentation.
- Indie hackers building voice products where transcription quality in ugly real-world audio matters more than chasing the smallest model size.
Not ideal for:
- Teams that only transcribe studio-quality speech and do not care about hard acoustic conditions.
- Products that need a tiny on-device footprint first and model quality second.
- Buyers who want a polished commercial SDK, SLA, or turnkey enterprise support package.
Key Features of Mega-ASR
-
7 atomic acoustic conditions — Mega-ASR is trained around discrete failure modes such as noise, far-field speech, obstruction, echo and reverberation, recording artifacts, electronic distortion, and transmission dropout. That gives you coverage over the specific degradations that normally cause ASR regressions in production.
-
54 compound acoustic scenarios — The model does not just see isolated noise; it is exposed to condition combinations that resemble messy reality. That matters because real calls and field recordings rarely fail for one reason only.
-
2.6M training samples — The page states that Mega-ASR was built on 2.6 million training samples, which is large enough to encode wide acoustic diversity without relying on one narrow benchmark distribution. For engineering teams, that usually means fewer surprises when moving from a curated test set to live traffic.
-
A2S-SFT training stage — The repo describes a supervised fine-tuning stage named A2S-SFT. Even without a full architecture dump on the landing page, the presence of a dedicated SFT phase tells you this is not a naive one-pass fine-tune; the model is being adapted with a structured curriculum.
-
DG-WGPO-based RL optimization — The project also uses DG-WGPO-based reinforcement learning. That is a strong signal that the authors are pushing the model to behave better on difficult samples instead of only optimizing average-case transcripts.
-
Benchmark-backed evaluation — Mega-ASR is paired with the Voices-in-the-Wild-Bench dataset and comparison tables against Qwen3-ASR, Gemini-3-Pro, Seed-ASR, and Whisper. In the page examples, the model is the only one that stays remotely usable on several corrupted clips, which is the whole point of this category.
-
Hugging Face distribution — The page links both the dataset and the weights on Hugging Face, which makes the project easier to reproduce than a paper-only release. That is important for anyone who wants to validate results in a Python pipeline instead of reading charts in isolation.
Mega-ASR vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| Mega-ASR | Hard-case transcription in noisy, real-world audio | Trained on 2.6M samples with 7 atomic conditions and 54 compound scenarios | Open-Source |
| Whisper | General-purpose ASR with broad adoption | Huge ecosystem, stable baseline, strong community tooling | Open-Source |
| Qwen3-ASR | Teams already aligned with the Qwen ecosystem | Model-family consistency and vendor-backed releases | Open-Source |
| Gemini-3-Pro | Cloud-first multimodal workflows | General assistant stack beyond pure transcription | Paid |
Pick Whisper when you want the safest reference baseline and do not need the extra specialization for ugly acoustic conditions. Whisper is still the easiest comparison point when you are documenting deltas for stakeholders.
Pick Qwen3-ASR when you want a family-aligned alternative and you are already standardizing on Qwen models in your stack. It is the more obvious choice if your team cares about ecosystem consistency more than a custom robustness recipe.
Pick Gemini-3-Pro when transcription is only one part of a larger cloud workflow and you want a broader managed API. It is not the first choice if your main constraint is raw ASR resilience on corrupted audio.
If you are building adjacent voice experiences rather than a pure benchmark harness, Moonshine Voice is a better fit for lightweight voice product experiments, while OpenTrace is the tool you want once you start tracing decode latency, retries, and failure paths in production. If you want to browse the broader ecosystem, see browse all AI Speech Recognition Models.
How Mega-ASR Works
Mega-ASR is built around a simple engineering thesis: if the model only sees clean speech, it will fail the minute the microphone, room, codec, or transport layer gets messy. The project attacks that problem by synthesizing or curating training data around atomic acoustic conditions, then combining them into compound scenarios that resemble real deployment traffic.
The data model is the important design choice here. Instead of treating noise as one blob, Mega-ASR decomposes the environment into distinct corruption types, which lets the training process cover far-field capture, echo, obstruction, and transmission failure as separate failure surfaces before recombining them into more realistic mixed cases.
The repo also makes the optimization stack explicit: A2S-SFT followed by DG-WGPO-based RL. That says the authors care about both supervised learning on the right distribution and a later corrective stage that pushes the model toward better behavior on hard examples, which is exactly what you want if your target is production transcription rather than leaderboard vanity metrics.
git clone https://github.com/xzf-thu/Mega-ASR.git
cd Mega-ASR
python -m venv .venv && source .venv/bin/activate
pip install -U torch torchaudio transformers datasets huggingface_hub
huggingface-cli download zhifeixie/Mega-ASR --local-dir ./weights
python tools/infer.py --model ./weights --audio ./samples/noisy_call.wav
This pulls the project, installs a minimal Python inference stack, downloads the released weights, and runs a first decode against a noisy clip. Expect the first run to spend most of its time downloading model assets and initializing the runtime, not parsing the command wrapper.
Pros and Cons of Mega-ASR
Pros:
- Strong focus on real acoustic corruption instead of clean-audio vanity benchmarks.
- Large training set size at 2.6M samples, which helps cover more failure modes.
- Explicit modeling of both atomic and compound scenarios, which better matches production audio.
- Public weights and dataset links on Hugging Face make reproduction straightforward.
- The page includes side-by-side WER examples, which makes quality assessment faster than reading a paper abstract.
- Good fit for speech systems that must survive phone audio, field recordings, and low-quality capture chains.
Cons:
- The landing page does not document a polished SDK, package layout, or one-command production integration.
- License and release version are not clearly stated in the page text, which adds legal and operational uncertainty.
- It is not the obvious choice for tiny edge devices where model size and CPU latency dominate.
- The project is specialized for hard acoustic environments, so it may be overkill for clean studio transcription.
- Benchmark gains are compelling, but teams still need to validate on their own domain audio before treating the model as a drop-in replacement.
Getting Started with Mega-ASR
The fastest way to evaluate Mega-ASR is to clone the repo, install a Python ASR stack, download the released weights, and run one noisy audio file through the inference entrypoint. The Hugging Face links on the page make this a low-friction experiment if you already have a GPU box or a decent local workstation.
git clone https://github.com/xzf-thu/Mega-ASR.git
cd Mega-ASR
python -m venv .venv && source .venv/bin/activate
pip install -U torch torchaudio transformers datasets huggingface_hub
huggingface-cli download zhifeixie/Mega-ASR --local-dir ./weights
python tools/infer.py --model ./weights --audio ./samples/noisy_call.wav
After the first run, you should verify the model on at least one clean clip and one corrupted clip from your own domain. If your deployment path depends on GPUs, CUDA, or audio pre-processing, configure those pieces before you compare WER numbers, because runtime setup can distort the first pass.
Verdict
Mega-ASR is the strongest option for noisy, real-world transcription when clean-audio ASR breaks under far-field speech, obstruction, or dropout. Its biggest strength is the combination of 2.6M samples and scenario-aware training; its main caveat is the lack of a clearly documented production SDK or license in the page text. If your workload is ugly audio, use Mega-ASR first.