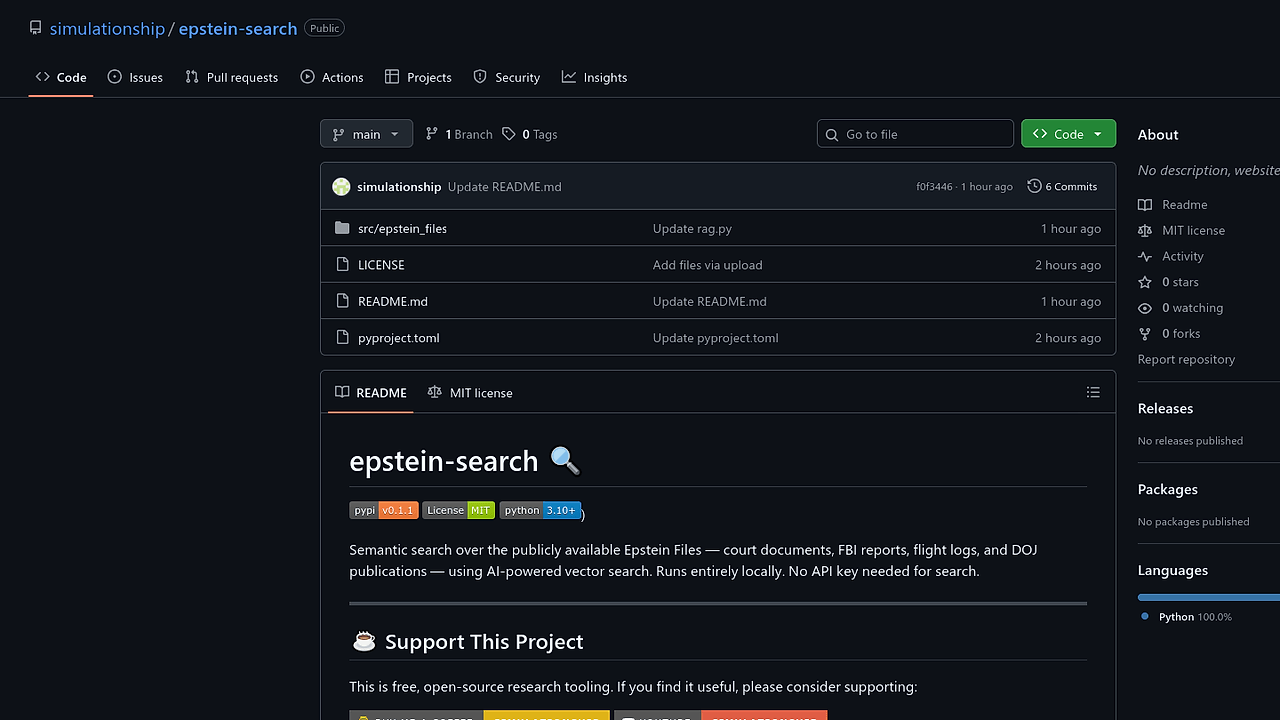
epstein-search: Local-First Killer of Manual Document Dumps
epstein-search nukes sifting through raw Epstein court filings, FBI reports, and flight logs by PDF. It pre-chunks and embeds 100K+ public documents into a local vector index for instant semantic queries. Ditch keyword grep or paid discovery tools—this handles sworn depositions and financial wires offline.
Under the Hood: Pre-Built Vector Index + LiteLLM RAG
epstein-search ships a pyproject.toml-based Python CLI that downloads a pre-computed FAISS-like vector store (~1-2 min setup) from document splits by type (court_filing, deposition, fbi_report, flight_log, financial). Queries hit cosine similarity on Gemini Flash or Ollama Llama3 embeddings via LiteLLM proxy, which routes to local servers (Ollama, LM Studio on port 1234) or cloud (OpenAI, Anthropic). RAG mode fetches top-K chunks, stuffs into LLM prompt; search mode dumps raw snippets with --json-output or --source filters.
The Good & The Bad
Pros:
- Zero API for core search—pure local vectors after
epstein-search setup. - Swappable LLMs mid-chat via
/model anthropic/claude-haikuor.envdefaults. - Granular filters like
--doc-type flight_logor--source FBIprune 100K chunks fast. - Interactive REPL with
/topk 5,/ask,/searchtoggles sources on/off. - JSON output for scripting:
epstein-search search "testimony" --json-output. - Plays with free local setups: Ollama Mistral or LM Studio without keys.
Cons:
- Locked to Epstein docs only—no general corpus ingestion.
- 1-2GB index download bloats disk on setup.
- Cloud LLMs need keys (GEMINI_API_KEY); local Ollama chews RAM for bigger models.
- No custom embedding fine-tuning or multi-user indexing.
- CLI-only—no GUI or web demo for quick peeks.
Quickstart
pip install epstein-search
epstein-search setup # downloads/indexes 100K+ chunks in 1-2 min
epstein-search chat # launches REPL for queries
setup builds the local vector store from pre-chunked Epstein files (court docs to flight logs). chat drops you into an interactive prompt—type "who's on the flight logs?" for top-10 semantic matches. Hit /model ollama/llama3 for free local inference or /quit to bail.
Who Should Use This (and Who Shouldn't)
Use it if: You're a solo investigator cross-referencing FBI reports with depositions offline; scripting RAG pipelines on niche corpora; testing LiteLLM routing without infra hassle.
Skip it if: You need general-purpose search beyond Epstein files; handling massive custom datasets (no upload API); preferring GUI over CLI for non-devs; running on low-RAM devices (Ollama Llama3 demands 8GB+).
Alternatives & When to Switch
Pick Haystack if building custom RAG on your own PDFs—supports Elasticsearch backends over fixed indexes. Go RAGFlow for self-hosted web UI on diverse docs, skipping CLI purity. Use LanceDB raw if you want vector DB primitives without Epstein bloat or LLM glue.