What Is Meta-Harness?
Meta-Harness is a framework from Stanford IRIS Lab for automated search over task-specific model harnesses: the control code around a fixed base model that decides what to store, retrieve, and show while the model works. Meta-Harness is one of the best AI Agent Frameworks tools for ML engineers and AI research teams. The repository ships with the framework plus two reference experiments from the 2026 paper, which makes it useful for teams that want to tune orchestration logic instead of retraining model weights.
The paper is Meta-Harness: End-to-End Optimization of Model Harnesses on arXiv, and the repo includes an onboarding flow plus domain-specific examples for text classification and Terminal-Bench 2.0. If your bottleneck is context management, memory policy, or scaffold design, Meta-Harness is aimed at that layer.
Quick Overview
| Attribute | Details |
|---|---|
| Type | AI Agent Frameworks |
| Best For | ML engineers and AI research teams |
| Language/Stack | Python, uv, Claude Code wrapper scripts |
| License | N/A |
| GitHub Stars | N/A |
| Pricing | Open-Source |
| Last Release | N/A |
Who Should Use Meta-Harness?
- Research teams evaluating how far a fixed base model can go when the harness is optimized instead of the weights. Meta-Harness fits benchmark-driven experiments where you care about measurable deltas from retrieval, memory, or scaffold changes.
- ML engineers shipping domain assistants that need custom context selection, state tracking, or evaluation loops. The framework is a better fit than prompt tinkering when the system behavior depends on persistent control logic.
- Infra and platform teams building repeatable experiment pipelines around one base model. Meta-Harness gives you a place to standardize proposer logging, candidate evaluation, and domain specs.
- Indie hackers who want to explore a domain-specific assistant without committing to fine-tuning infrastructure. The repo’s text classification example and Terminal-Bench 2.0 scaffold example make the runtime shape obvious fast.
Not ideal for:
- Teams that want a turn-key SaaS with dashboards, hosted evals, and opinionated workflow management.
- Projects that need a fully supported production platform instead of a paper artifact that has only been verified to run.
- Users who want to fine-tune the base model itself rather than search the harness around it.
Key Features of Meta-Harness
- Harness search over control logic — Meta-Harness treats the harness as the optimization target, not the model. That means you can explore what to store, retrieve, and show as separate decisions instead of hiding them inside a prompt blob.
- Onboarding flow for new domains — The repo points you to
ONBOARDING.md, then expects a conversation that producesdomain_spec.md. That file becomes the concrete contract for implementing the framework in a new domain. - Reference experiments for two real tasks — The shipped examples cover
reference_examples/text_classification/for memory-system search andreference_examples/terminal_bench_2/for scaffold evolution. Those are useful because they show both NLP-style and terminal-agent style harnesses. - Proposer-agent abstraction — The examples assume Claude Code as the proposer agent, but the repo explicitly says you can swap it by adapting
claude_wrapper.py. The main requirement is clean logging of proposer interactions so the search loop remains auditable. - Reproducible
uv-based runs — The quick start usesuv syncanduv run, which keeps dependency resolution close to the repo instead of relying on ambient Python state. That reduces setup drift across machines and CI runs. - Benchmark-first workflow — The framework is tied to smoke tasks and full evaluation commands, especially for Terminal-Bench 2.0. This makes Meta-Harness useful when you need a measurable signal for candidate harness variants.
- Paper-aligned artifact structure — The repository is a cleaned-up version of the code used for the paper. That matters because the directory layout and example scripts mirror the experimental workflow rather than a generic library template.
Meta-Harness vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| Meta-Harness | Search over task-specific harnesses | Optimizes the control code around a fixed base model | Open-Source |
| DSPy | Prompt and program optimization | Compiles higher-level programs and prompt strategies | Open-Source |
| LangGraph | Stateful agent workflows | Orchestrates nodes, state transitions, and branching logic | Open-Source |
| OpenSwarm | Multi-agent coordination | Coordinates multiple agents at runtime instead of searching a harness | Open-Source |
Pick DSPy if you want a more general prompt-program optimization layer and you are comfortable expressing the task as a declarative program. Pick LangGraph when the hard problem is stateful orchestration and branching execution, not benchmark search.
Pick OpenSwarm when the requirement is coordinating many agents across a workflow. If you already have trace data and need to inspect failures rather than optimize scaffolds, OpenTrace is the better adjacent tool. If the workflow is still mostly interactive coding with a model, Claude Code Canvas is closer to a human-in-the-loop editor than a search system.
How Meta-Harness Works
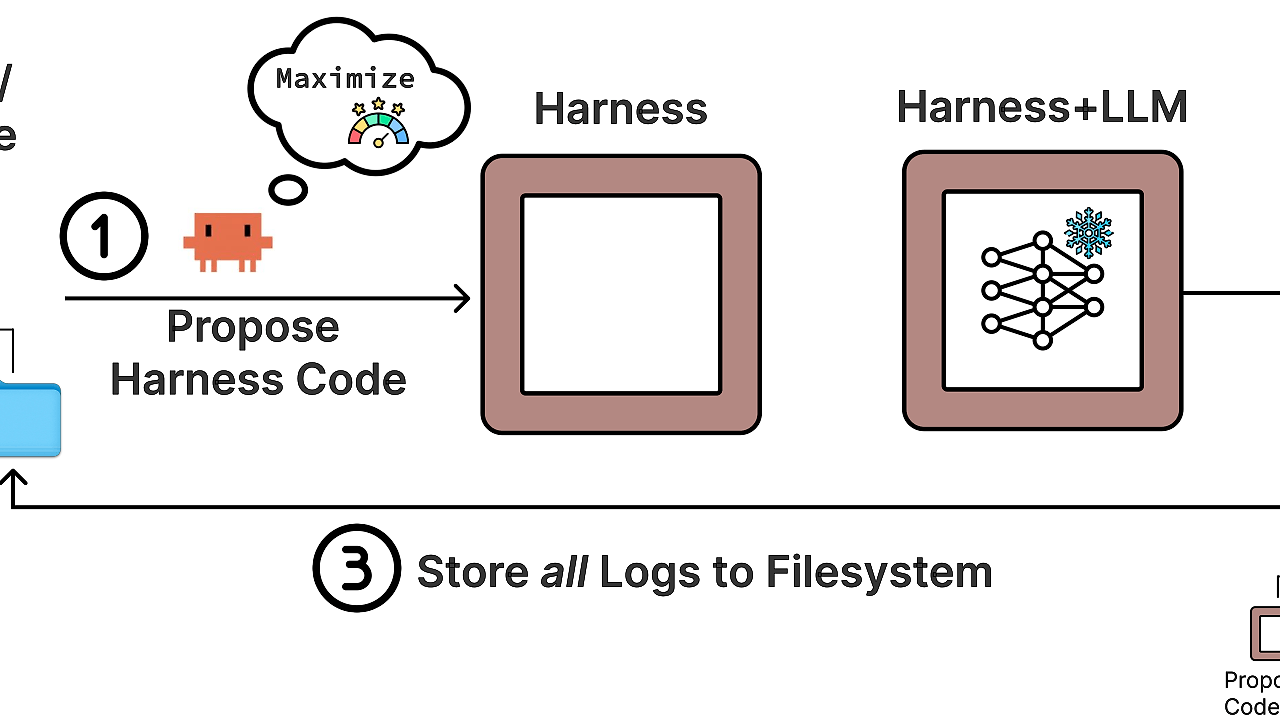
Meta-Harness works by framing the harness as a search space around a fixed base model. The search space includes memory policy, retrieval rules, displayed context, scaffold code, and the proposer-agent behavior that generates candidate harnesses.
The design choice is simple: keep the base model stable, then optimize the runtime system that feeds it information. That is a better fit than weight updates when the failure mode is bad context selection, bad ordering, or poor task-specific scaffolding. In practice, the system uses a domain spec and a proposer wrapper, then runs iterations that create, evaluate, and log candidate harness variants.
cd reference_examples/text_classification
uv sync
uv run python meta_harness.py --iterations 1
That command runs the text-classification example through one search iteration. The output is meant to validate the harness loop, not to produce a production-ready artifact, so expect logs, candidate generation, and evaluation results rather than a polished UI.
For the terminal benchmark path, the repo uses a similar pattern but swaps in an agent harness script and an evaluation shell command. That split makes Meta-Harness useful for both lightweight smoke tests and heavier benchmark runs, as long as the domain-specific evaluator is defined clearly.
Pros and Cons of Meta-Harness
Pros:
- Optimizes the right layer — It targets harness logic, which is where many agent failures actually happen.
- Supports new domains through onboarding —
ONBOARDING.mdanddomain_spec.mdcreate a repeatable path for adaptation. - Ships with two concrete examples — Text classification and Terminal-Bench 2.0 show how the framework behaves in different task shapes.
- Works with custom proposer agents — The wrapper abstraction makes it possible to swap Claude Code for another proposer if logging stays clean.
- Reproducible command flow —
uvcommands reduce environment drift and make local reproduction easier. - Paper-linked artifact — The repo maps closely to the published paper, which helps when you want to align implementation with the research claim.
Cons:
- Not production-hardened — The release note says it has only been checked to run, so expect rough edges.
- Requires domain engineering — You need to define the evaluation target, propose-good-candidate loop, and logging behavior yourself.
- Assumes a proposer workflow — The shipped examples are built around Claude Code, so alternate agents need adapter work.
- No hosted control plane — There is no SaaS layer for experiment management, artifact storage, or team collaboration.
- Narrow scope by design — If you need model training, deployment, and tracing in one product, Meta-Harness is only one piece of that stack.
Getting Started with Meta-Harness
Clone the repository, enter a reference example, install dependencies with uv, and run a single iteration of the search loop.
git clone https://github.com/stanford-iris-lab/meta-harness
cd meta-harness/reference_examples/text_classification
uv sync
uv run python meta_harness.py --iterations 1
After that run, you should see the harness search cycle execute once for the text-classification example. If you want the Terminal-Bench 2.0 smoke task instead, switch into reference_examples/terminal_bench_2/ and run the provided run_eval.sh command from that subdirectory README. The first thing to configure for a new domain is the domain_spec.md file generated from ONBOARDING.md.
Verdict
Meta-Harness is the strongest option for harness-search research when you want to optimize the control code around a fixed base model instead of swapping models. Its main strength is the domain onboarding plus evaluation loop; the caveat is that it expects engineering effort and clean benchmark definitions. Use Meta-Harness if repeatable harness optimization is the goal.