What Is MiniMind-O?
MiniMind-O is a GitHub-hosted Open-Source Omni Model Framework built by Jingyao Gong; it fuses text, audio, and vision into one end-to-end model for research engineers and ML practitioners, and the mini pipeline can run in about 2 hours on a single RTX 3090. MiniMind-O is one of the best Open-Source Omni Model Frameworks tools for research engineers and ML practitioners building end-to-end multimodal assistants. The repo ships the model code, training data, inference scripts, and a technical report, with published backbones at roughly 115M and 312M parameters as of 2026-05-05.
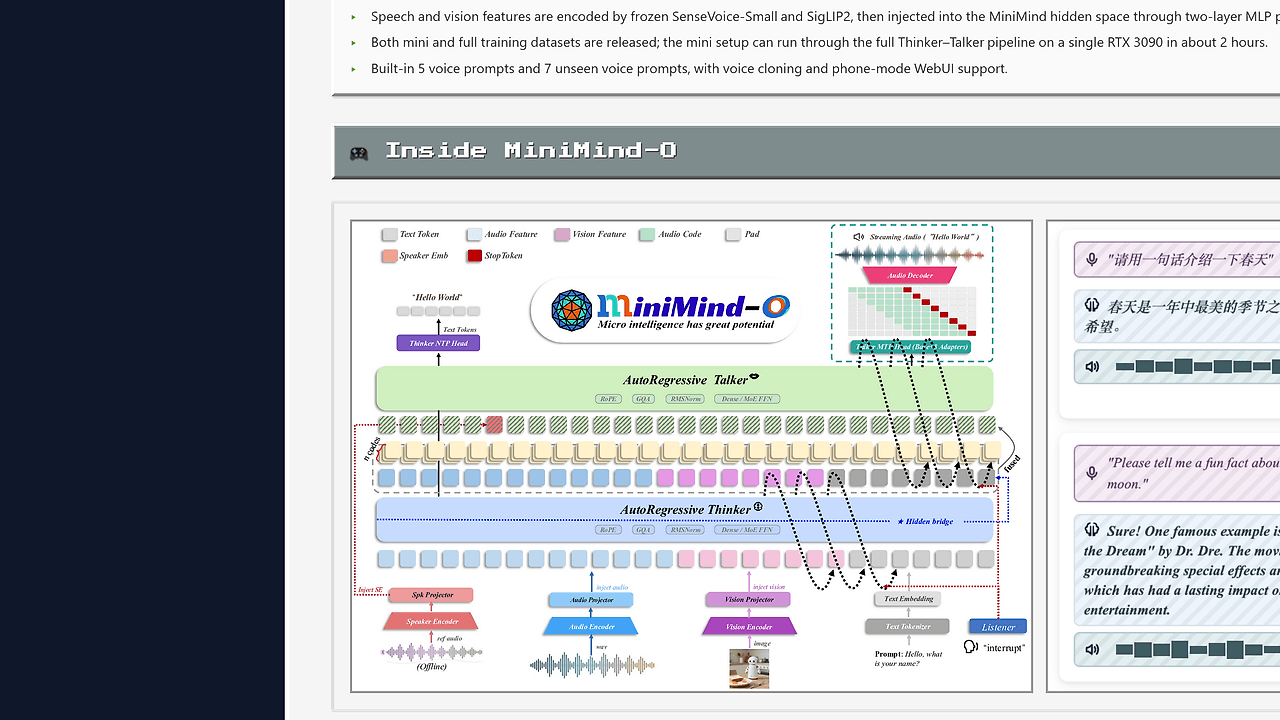
The point of MiniMind-O is not to bolt ASR, LLM, and TTS together as separate services. It keeps speech and text connected at the hidden-state level, then uses a Thinker–Talker split to produce semantic responses and streamable audio in a single loop.
Quick Overview
| Attribute | Details |
|---|---|
| Type | Open-Source Omni Model Frameworks |
| Best For | research engineers and ML practitioners building end-to-end multimodal assistants |
| Language/Stack | PyTorch, Mimi audio codes, SenseVoice-Small, SigLIP2, CAMPPlus, transformers-compatible tokenizers, Gradio |
| License | N/A |
| GitHub Stars | N/A as of May 2026 |
| Pricing | Open-Source |
| Last Release | minimind-3o / minimind-3o-moe — 2026-05-05 |
MiniMind-O is designed as a full-stack reference implementation, not a thin demo wrapper. The repo includes training code, released weights, datasets, CLI inference, WebUI, barge-in support, telephone mode, and voice cloning paths that are meant to be inspected and modified.
Who Should Use MiniMind-O?
- Multimodal research engineers who want to read one codebase end to end and understand how a streaming Omni model is assembled from encoders, projectors, and a dual-path decoder.
- ML practitioners with a single strong GPU who need a small but complete training target, especially if they want to validate a speech-to-speech or image-to-speech pipeline on one RTX 3090.
- Indie hackers building voice assistants who care about local inference, inspectable weights, and a model they can adapt instead of a closed API.
- Teams studying multimodal architecture trade-offs who want a practical baseline for comparing hidden-state fusion against ASR -> LLM -> TTS cascades.
Not ideal for:
- Production teams needing SLO-backed vendor support and a managed uptime contract.
- Organizations that only need inference and do not care about training internals, projector layers, or audio token prediction.
- Users expecting plug-and-play quality at frontier scale from a sub-billion-parameter Omni model.
Key Features of MiniMind-O
- Thinker–Talker split — MiniMind-O separates semantic reasoning from audio generation. The Thinker handles text, speech, and vision understanding, while the Talker predicts Mimi codes for streaming speech output, which keeps the architecture inspectable and easy to reason about.
- MTP audio decoding — The Talker uses Multi-Token Prediction to predict multiple layers of Mimi codes at once. That reduces the gap between semantic intent and audio synthesis and is the core trick behind the model's streaming speech path.
- Streaming speech with barge-in — The repo explicitly supports VAD-driven interruption and near-duplex interaction. That means a user can interrupt generated speech without waiting for the full utterance to finish, which is essential for voice UI latency.
- Vision and audio projectors — Frozen SenseVoice-Small and SigLIP2 encoders feed into lightweight MLP projectors before entering the MiniMind hidden space. This design keeps modality-specific encoders stable while making the fusion layers cheap to retrain.
- Full training pipeline — MiniMind-O includes SFT flows for T2A, I2T, and A2A data, plus support for full-parameter training, audio projector training, visual projector training, and DDP multi-GPU execution. That makes it useful as a lab reference for modality-specific ablations.
- Local inference and WebUI — The repo ships a CLI path through
eval_omni.pyand a Gradio-based WebUI for streaming playback, telephone mode, and voice cloning experiments. You can test behavior without wiring up external services. - Two dataset scales — The mini dataset is meant to finish a complete chain on one RTX 3090 in about 2 hours, while the full dataset aligns with the released weights. That split is valuable for fast iteration before you pay the full training cost.
MiniMind-O vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| MiniMind-O | End-to-end Omni research and small-scale training | From-scratch PyTorch implementation with Thinker–Talker, MTP audio, and streaming barge-in | Open-Source |
| Qwen3-Omni | Higher-capability general-purpose multimodal inference | Larger frontier-style Omni model with stronger production readiness | Open-Source |
| Moshi | Real-time speech-first interaction research | Optimized for low-latency conversational audio and duplex-style interaction | Open-Source |
| GPT-4o | Teams that want best-in-class API quality | Managed hosted model with no training burden | Paid |
Pick Qwen3-Omni if you need a stronger baseline and do not care about learning the full implementation details. Pick Moshi if your main constraint is conversational latency and you want a speech-centric reference system.
Pick GPT-4o when you want the highest abstraction level and are fine paying for a closed API. Pick MiniMind-O when you need the code, the weights, the data, and the training path in one repo, which is the difference between using a model and understanding it.
If you want orchestration around the model rather than the model itself, pair MiniMind-O with OpenSwarm for agent-style workflows. If you are comparing it against other open model stacks, browse all AI model tools to map the surrounding ecosystem.
How MiniMind-O Works
MiniMind-O uses a dual-path Omni design. The Thinker path consumes text directly and converts audio and vision into shared hidden representations, while the Talker path turns semantic state into Mimi audio codes that are later decoded into waveform output.
The architecture avoids a pure pipeline like ASR -> LLM -> TTS because that introduces extra latency and strips away some speech properties before reasoning happens. Instead, MiniMind-O keeps speech, text, and image inputs closer to the model core, then uses a shared backbone with lightweight modality projectors and an audio head to produce streaming speech.
# getting started example
cd trainer
CUDA_VISIBLE_DEVICES=0 torchrun --master_port 29560 --nproc_per_node 1 \
train_sft_omni.py --learning_rate 5e-4 \
--data_path ../dataset/sft_t2a_mini.parquet \
--epochs 1 --batch_size 40 --use_compile 1 \
--from_weight llm --save_weight sft_zero \
--max_seq_len 512 --use_wandb --use_moe 0
That command runs the first stage of the mini SFT chain on one GPU and writes checkpoints for later stages. Expect the first pass to build the speech-text alignment before you move into audio projection and full multimodal tuning.
Pros and Cons of MiniMind-O
Pros:
- Single-repo completeness — code, data, weights, evaluation, and demos are all published together.
- Small enough to study — the 115M-class backbone is realistic for reading, profiling, and patching.
- Real streaming behavior — barge-in and near-duplex speech are implemented, not described abstractly.
- PyTorch-native implementation — core modules are not hidden behind a heavy third-party abstraction layer.
- Modality-specific encoders are frozen — SenseVoice-Small and SigLIP2 reduce retraining noise and make the fusion layers easier to analyze.
- Fast mini training loop — the mini dataset gives you a short feedback cycle on one RTX 3090.
Cons:
- Quality is bounded by size — a 0.1B-class Omni model will not match frontier hosted models on broad generalization.
- Requires local setup work — you must download encoders, base weights, and datasets manually before training or inference.
- Research-first ergonomics — the repo is optimized for understanding and experimentation, not enterprise deployment.
- More moving parts than a pure API — you still manage checkpoints, codecs, and modality assets.
- License details are unclear from the scraped page — you should verify repository licensing before commercial redistribution.
Getting Started with MiniMind-O
Clone the repository, install dependencies, download the encoders and base weights, then run inference or the mini training pipeline. The quickstart below mirrors the repo's documented path and gets you to a first answer with minimal guessing.
# clone and install
it=0
if [ "$it" -eq 0 ]; then
git clone --depth 1 https://github.com/jingyaogong/minimind-o
cd minimind-o
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
fi
# download required assets
modelscope download --model gongjy/SenseVoiceSmall --local_dir ./model/SenseVoiceSmall
modelscope download --model gongjy/siglip2-base-p32-256-ve --local_dir ./model/siglip2-base-p32-256-ve
modelscope download --model gongjy/mimi --local_dir ./model/mimi
modelscope download --model gongjy/campplus --local_dir ./model/campplus
modelscope download --model gongjy/minimind-3o-pytorch llm_768.pth --local_dir ./out
# first inference pass
python eval_omni.py --load_from model --weight sft_omni
After the first inference run, MiniMind-O expects the model assets to be present under ./model and ./out. If you want the WebUI, copy the Hugging Face model folder into ./scripts/ and launch python web_demo_omni.py; if you want training, start with the mini parquet datasets and move to the full chain only after the first stage is stable.
Verdict
MiniMind-O is the strongest option for studying and modifying an end-to-end Omni model when you want the full training and inference stack in one PyTorch repo. Its main strength is the honest architecture: separate Thinker/Talker paths, streaming speech, and published assets. Its caveat is scale, so choose it for learning and prototyping first, not for frontier-quality production replacement.