Open R1: Reproducing DeepSeek-R1
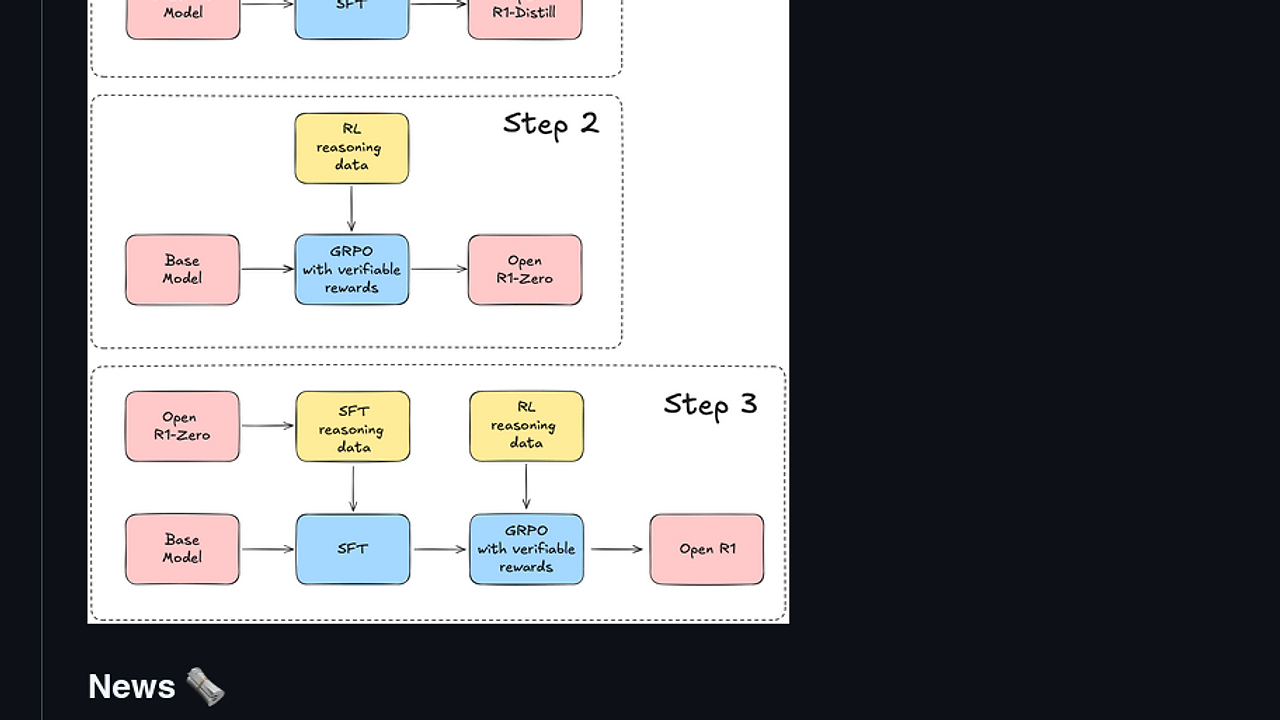
Open R1 implements the full pipeline to distill and train reasoning models matching DeepSeek-R1-Distill-Qwen-7B from base Qwen models. It targets the black-box nature of proprietary reasoning chains by generating open datasets like Mixture-of-Thoughts (350k traces) and CodeForces-CoTs (100k solutions). Developers ditch closed APIs for self-hosted GRPO and SFT on synthetic math, code, and science data.
Under the Hood: GRPO and SFT Pipeline
Core scripts in src/open_r1 drive the process: grpo.py applies GRPO (Group Relative Policy Optimization) for RL tuning without explicit rewards, using TRL library on vLLM inference. sft.py runs supervised fine-tuning via standard Hugging Face Trainer on datasets like OpenR1-Math-220k from NuminaMath traces. generate.py leverages Distilabel to distill traces from DeepSeek-R1 or smaller proxies, aligning EOS tokens across tokenizer and generation config. Makefile orchestrates steps with bumped vLLM/TRL versions, SLURM jobs for scaling, and eval on GPQA Diamond plus IOI24 benchmarks.
The Good & The Bad
Pros:
- Matches DeepSeek-R1-Distill-7B performance on math/reasoning after SFT on 220k-350k distilled traces.
- Open datasets (e.g., CodeForces-CoTs) enable 7B Qwen to beat Claude 3.7 Sonnet on IOI24 olympiad problems.
- Simple Makefile targets handle distillation, SFT, GRPO, and evals without custom infra.
- vLLM integration speeds inference for data generation at scale.
- Apache-2.0 license allows unrestricted forking and commercial use.
- Reproducible evals fix DeepSeek's GPQA Diamond scores via dataset mixer.
Cons:
- CUDA 12.4 dependency triggers segfaults on mismatched drivers—check
nvcc --versionfirst. - Data gen from full R1 needs API access; fallback to smol distill models slows iteration.
- GRPO stage demands curated large-scale datasets you must build post-distillation.
- No pre-trained checkpoints; full pipeline from Qwen base takes serious GPU hours.
- SLURM scripts assume cluster env—local runs hit OOM on >7B without tweaks.
Quickstart
uv venv && source .venv/bin/activate
pip install -e .
make distill # Generates Mixture-of-Thoughts from R1 or proxy
make sft # SFT Qwen-7B on distilled math/code traces
make grpo # RL tune with GRPO
make eval # Run GPQA/IOI24 benchmarks
These commands set up a virtualenv, install deps, distill 350k traces across math/science/code, fine-tune base Qwen-7B to match R1-Distill perf, apply GRPO for zero-shot reasoning gains, and eval against olympiad-hard benchmarks. Expect 7B model to hit R1-level on NuminaMath after SFT; scale to 32B for IOI24 leadership.
Who Should Use This (and Who Shouldn't)
Use it if: You're an ML engineer replicating reasoning chains on Qwen bases for math-heavy agents. Ideal for teams curating synthetic data at 100k+ scale before GRPO. Fits indie researchers benchmarking open alternatives to o1-preview.
Skip it if: You lack 8x A100s for distillation/SFT—single RTX 4090 chokes on 32B. Avoid if targeting non-reasoning tasks like chat; base HF Trainer suffices. Wrong for prod deployment without further quantization.
Alternatives & When to Switch
If you need one-shot SFT without distillation, use Axolotl—simpler YAML configs beat Makefile for quick LoRAs. Pick TRL directly if GRPO isn't core; its PPO/DPO scripts avoid Open R1's data-gen overhead. For closed-source equiv, DeepSeek-R1 API skips all training but locks you into their traces.