What Is audit?
audit is one of the best AI Vulnerability Discovery Agents tools for AppSec teams, security researchers, and senior engineers, and it was built by evilsocket as an MIT-licensed Python repo. It runs an 8-stage pipeline that fans out into narrow Hunt tasks, then forces validation, deduplication, and reachability tracing so the final report only keeps findings that can survive adversarial review. The default workflow can generate 15-50 Hunt tasks on a real codebase, which makes the system useful for large repos where single-pass LLM prompts miss context.
Quick Overview
| Attribute | Details |
|---|---|
| Type | AI Vulnerability Discovery Agents |
| Best For | AppSec teams, security researchers, and senior developers |
| Language/Stack | Python, Claude Code Agent SDK, Anthropic Messages API, JSON Schema, YAML prompts |
| License | MIT |
| GitHub Stars | N/A |
| Pricing | Open-Source |
| Last Release | N/A |
Who Should Use audit?
- AppSec engineers who need an agentic workflow that can map a repository, propose attack surfaces, and pressure-test findings before they reach a human reviewer.
- Security researchers looking for a reproducible harness that turns wide-codebase exploration into structured Hunt tasks instead of one giant prompt that drifts.
- Platform teams responsible for monorepos or many services where reachability matters more than raw pattern matches.
- Indie hackers and CTOs who want a practical security pass over private code without wiring together a custom orchestration stack.
Not ideal for:
- Teams that want a zero-configuration static scanner with no model auth, no gateway setup, and no budget controls.
- Repos where you only need deterministic lint-style findings and do not want agentic exploration or model-driven reasoning.
- Organizations that cannot use Claude-compatible tooling or do not want to manage subscription OAuth, gateways, or per-stage model policy.
Key Features of audit
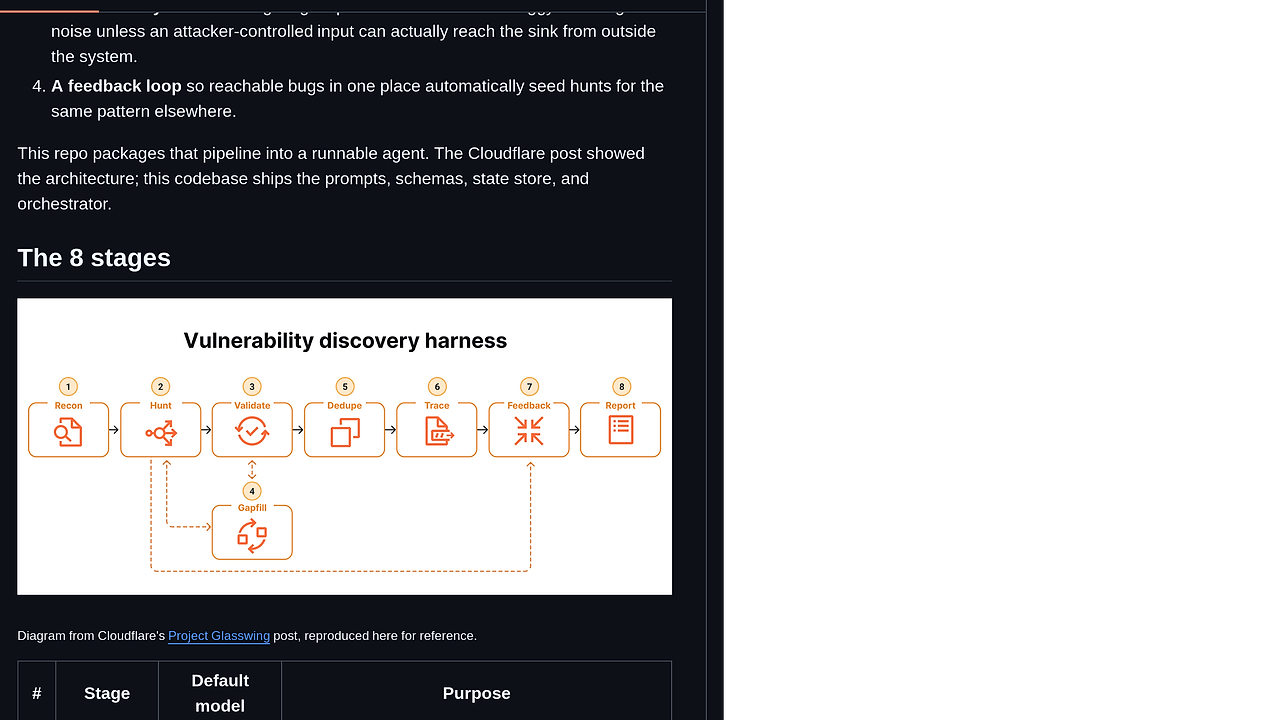
- 8-stage security pipeline — audit splits work into Recon, Hunt, Validate, Gapfill, Dedupe, Trace, Feedback, and Report. That structure matters because each stage has a narrower job and a different default model, which reduces the chance that one agent hallucinates both the bug and the proof.
- Narrow-agent fanout — Recon emits tightly scoped Hunt tasks like a specific sink, trust boundary, or attack class. That makes audit behave more like a security research team than a generic chatbot, and it avoids the common failure mode where one agent tries to solve the whole repository at once.
- Adversarial validation — Validate uses a different model from Hunt and is explicitly asked to disprove the original finding. This is the strongest anti-confirmation-bias feature in audit because it treats every result as guilty until a second model fails to kill it.
- Reachability gating — Trace must prove attacker-controlled input can reach the sink before a report is treated as real. This is where audit beats simple code search, because a vulnerable line that no attacker can hit is usually noise in a triage queue.
- Schema-stable outputs — Each stage is backed by a markdown prompt in
prompts/and a JSON Schema inschemas/, then the orchestrator injects the schema into the system prompt. That design keeps outputs machine-readable on the first pass and makes it much easier to chain stages without brittle parsing glue. - Provider flexibility — audit can run through Claude subscription OAuth, a headless token from
claude setup-token, or an Anthropic-compatible gateway such as OpenRouter. If you already have gateway infrastructure, that means audit can fit into an existing model budget instead of forcing a new vendor path. - Cost guardrails and live-target mode — the runner can cap concurrency, initial task fanout, and total spend with
--max-concurrency,--max-recon-tasks, and--max-cost-usd. When--target-urlis set, audit can reproduce findings against a live service and reject anything that does not reproduce, which is a much better signal than local-only PoC generation.
audit vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| audit | Agentic vulnerability discovery with reachability proof | Eight-stage workflow with adversarial validation and feedback loops | Open-Source |
| Semgrep | Fast rule-based scanning in CI | Deterministic pattern matching and custom rules | Free / Paid |
| CodeQL | Deep semantic code querying | Tainted-flow queries and large-scale code analysis | Free / Paid |
| OpenSwarm | General multi-agent orchestration | Broader agent coordination without a security-specific pipeline | Open-Source |
Pick Semgrep when you want quick, deterministic checks for known anti-patterns and you are optimizing for CI speed. Pick CodeQL when you need semantic queries over a large polyglot estate and your team already maintains a query pack.
Use OpenSwarm when you need flexible multi-agent orchestration for non-security work, such as research or planning, and you do not need audit's fixed reachability gate. If you only need to validate sink reachability after another scanner flags something, pair the workflow with OpenTrace instead of rerunning the full audit pipeline.
How audit Works
audit is built around a simple security thesis: narrow questions beat one giant prompt, and disagreement beats self-confirmation. The orchestrator reads stage prompts from prompts/, validates every stage against JSON Schemas in schemas/, and stores the state needed to move from recon to final report. The default stage split uses Opus 4.7 for higher-trust reasoning steps and Sonnet 4.6 for fanout-heavy work, so the system spends expensive reasoning only where it matters most.
audit also encodes an explicit feedback loop. Recon maps the repository and emits Hunt tasks, Hunt tries to reproduce a single attack class, Validate tries to break that result, and Trace proves whether attacker-controlled input can actually reach the sink. That feedback loop matters in codebases with repeated anti-patterns, because a reachable issue in one path can seed new Hunt tasks elsewhere without restarting the whole analysis.
audit run --repo /path/to/target --run-id my-run --max-concurrency 1 --max-cost-usd 30
audit status --run-id my-run
audit report --run-id my-run --format md > report.md
The first command starts the pipeline against a local repository, limits concurrency, and caps spend before the run can spiral. The status and report commands let you inspect stage progress and export a structured markdown result after the schemas have been validated.
Pros and Cons of audit
Pros:
- Reachability-first triage cuts down on false positives that never leave the static analysis or prompt stage.
- Different models for Hunt and Validate reduce confirmation bias and make it harder for one model to rubber-stamp its own output.
- Schema validation keeps stage outputs machine-parseable, which is critical when you want repeatable automation instead of chat logs.
- Gateway support lets you use OpenRouter or another Anthropic-compatible endpoint if you do not want to depend on the default Claude login path.
- Live-target reproduction gives you a practical signal on whether a bug exists in a deployed system, not just in source code.
- Budget controls help large repos avoid runaway agent fanout and make the tool usable in real-world CI or internal audit windows.
Cons:
- Claude-compatible auth is mandatory for the primary workflow, so this is not a drop-in tool for teams that banned that ecosystem.
- Non-Claude models may be less reliable at producing schema-compliant JSON, which means gateway freedom can trade off against output quality.
- Large repositories can get expensive fast because the default pattern is to fan out into many Hunt tasks before the dedupe and trace stages collapse them.
- Live-target mode narrows egress to one host and localhost, which is correct for safety but can be restrictive during broader integration testing.
- The pipeline is opinionated around security discovery, so it is not the right choice if you want a generic agent framework for unrelated automation.
Getting Started with audit
python -m venv .venv && source .venv/bin/activate
pip install -e .
claude login
audit auth-check
audit run --repo /path/to/target --run-id demo
If you prefer headless auth for CI, replace claude login with claude setup-token and export CLAUDE_CODE_OAUTH_TOKEN in your environment. After the first run, audit will create a run directory with stage artifacts, schema-validated outputs, and a report that you can inspect or export as markdown.
Verdict
audit is the strongest option for AppSec teams that want an agentic vulnerability-discovery pipeline when they already have access to Claude-compatible auth or a gateway. Its main strength is the combination of narrow agents, adversarial validation, and reachability tracing; the main caveat is cost and setup complexity on large repos. Use it when false positives are expensive and you need proof, not guesses.