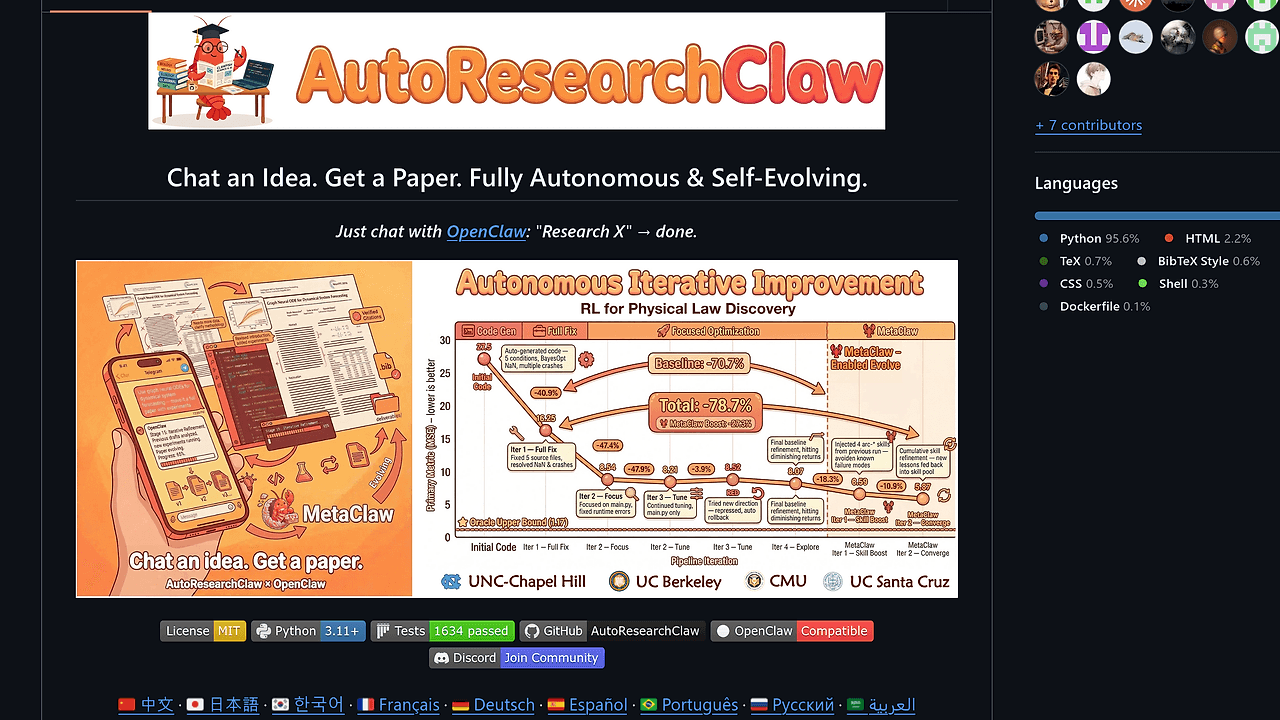
What Is Deep Researcher Agent?
Deep Researcher Agent is an open-source AI Research Agents project built by Xiangyue-Zhang for ML researchers, applied scientists, and AI engineers who want a 24/7 experiment loop instead of babysitting training runs. Deep Researcher Agent is one of the best AI Research Agents tools for ML researchers because it launches deep learning jobs, watches progress, updates memory, and keeps iterating with Claude Code and Codex CLI compatibility. The repo exposes Apache 2.0 licensing, Python 3.10+ support, and an arXiv technical report 2604.05854, while the scraped page does not expose a GitHub star count.
The practical value is not model training itself. The value is the orchestration layer around training: branch selection, log inspection, progress tracking, and controlled continuation after each cycle. That makes Deep Researcher Agent closer to a research ops copilot than a notebook helper.
Quick Overview
| Attribute | Details |
|---|---|
| Type | AI Research Agents |
| Best For | ML researchers, applied scientists, and AI engineers |
| Language/Stack | Python 3.10+, Claude Code, Codex CLI, PyTorch, NVIDIA GPUs |
| License | Apache 2.0 |
| GitHub Stars | N/A as of Apr 2026 |
| Pricing | Open-Source |
| Last Release | N/A |
Who Should Use Deep Researcher Agent?
Deep Researcher Agent fits people who already know the experimental direction and need the loop to keep moving without constant supervision.
- Solo ML researchers running repeated model sweeps who want an agent to launch, monitor, and summarize runs while they sleep.
- Applied scientists testing ablations, schedules, augmentations, or architecture changes where each cycle produces a clear next action.
- Small platform teams managing expensive GPU time and needing tighter control over trial boundaries, logs, and experiment memory.
- Indie hackers building niche model prototypes who want structured iteration without building an internal experiment manager first.
Not ideal for:
- Teams that need a fully autonomous system to invent research goals from scratch.
- Projects without GPU access, because Deep Researcher Agent expects at least one NVIDIA GPU for training.
- Users who cannot grant shell access or do not want an agent writing code and launching local jobs.
Key Features of Deep Researcher Agent
- Persistent experiment loop — Deep Researcher Agent does not stop at one training run. It keeps cycling through edit, launch, observe, decide, and repeat, which is the main reason it works for overnight experimentation instead of one-off scripting.
- Human control files — The workflow centers on
PROJECT_BRIEF.md,HUMAN_DIRECTIVE.md, andworkspace/MEMORY_LOG.md. That separation keeps the research goal stable, lets you inject a one-cycle override, and preserves the running history in a structured text trail. - Low-cost monitoring — Training-time monitoring uses zero LLM calls, so the agent does not waste tokens while a job is just running. The recent update on 2026-04-09 also reset leader context between cycles to reduce token growth.
- Progress visibility — Commands like
/experiment-statusand/progress-reportgive a machine-readable view of cycle count, best result, current goal, and recent decisions. That matters when a model run takes hours and you need a fast terminal check instead of opening ten logs. - Obsidian and local note sync — Deep Researcher Agent can export progress into an Obsidian vault, or fall back to
workspace/progress_tracking/when no vault is configured. That gives you persistent notes without coupling the workflow to one note-taking app. - Safety hardening — The 2026-04-09 update added defenses against path traversal and shell injection. That is a meaningful detail for any agent that writes files and executes commands on your machine.
- Claude Code and Codex CLI compatibility — The project is explicitly compatible with both toolchains, so teams already using agentic coding workflows can slot Deep Researcher Agent into the same environment. It pairs naturally with Claude Code Canvas when you want an interactive coding surface and with OpenTrace when you need execution-level visibility.
Deep Researcher Agent vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| Deep Researcher Agent | Long-running deep learning experiment loops | Stateful cycle control for launch, monitor, decide, repeat | Open-Source |
| OpenSwarm | Multi-agent task orchestration | Better fit for general autonomous task routing across agents | Open-Source |
| Claude Code Canvas | Interactive agentic coding sessions | More manual, more visual, less experiment-loop specific | Varies |
| Brainstorm MCP | Idea generation and planning | Better for exploring directions before committing to runs | Open-Source |
Pick Deep Researcher Agent when the hard problem is not ideation but disciplined iteration around a real training loop. Pick OpenSwarm when you want broader multi-agent coordination across workflows, not just experiment management.
Pick Claude Code Canvas when a human still wants to steer every coding step in a richer interface. Pick Brainstorm MCP when you need direction discovery and hypothesis generation before any GPU budget is spent.
How Deep Researcher Agent Works
Deep Researcher Agent uses a control-file driven state machine rather than a black-box autonomous loop. PROJECT_BRIEF.md defines the stable goal and constraints, HUMAN_DIRECTIVE.md acts as a temporary override for the next cycle, and workspace/MEMORY_LOG.md stores the rolling record of results, decisions, and the next planned move.
The design choice here is deliberate. Instead of letting the agent improvise in an unbounded chat, Deep Researcher Agent constrains the search space and keeps every meaningful decision tied to an artifact on disk. That makes the system easier to audit, easier to resume, and easier to stop when a branch is no longer paying for itself.
A typical start looks like this:
/auto-experiment --project /path/to/project --gpu 0
/experiment-status
The first command launches the loop against one project folder and pins work to GPU 0. The second command checks current goal, cycle count, running state, and recent decisions, which is the fastest way to verify that the agent is still on the path you intended.
The runtime also separates training from supervision. During an active job, the agent can track progress without asking the model to reason every second, which keeps token usage lower and reduces the chance of pointless no-progress loops. The 2026-04-09 fallback logic is especially relevant here because it avoids getting stuck in repeated dead-end iterations.
Pros and Cons of Deep Researcher Agent
Pros:
- Real experiment automation — It goes beyond code generation and actually manages the experiment lifecycle, which is the part most researchers waste time on.
- Human-in-the-loop by design — The brief/directive/memory split keeps control explicit instead of burying it in prompts.
- Low monitoring overhead — It avoids LLM calls during passive training monitoring, which helps when runs are long and frequent.
- Works with existing agent tooling — Claude Code and Codex CLI compatibility makes it easier to adopt in teams already using shell-based agents.
- Persistent progress artifacts — Obsidian sync and local text fallbacks make status durable across sessions and machines.
- Security hardening landed recently — The April 2026 update added practical protections around shell execution and file paths.
Cons:
- Requires a real GPU workflow — Deep Researcher Agent is not useful for CPU-only toy projects or non-training tasks.
- Not a research idea generator — It executes and iterates on your hypothesis, but it does not replace scientific judgment.
- Depends on clean project discipline — If
PROJECT_BRIEF.mdis vague, the loop will still be vague. - Shell access is a requirement — Teams with locked-down environments or strict execution policies will have deployment friction.
- Repository-level star and release metadata are sparse in the scraped text — You should verify current community traction before standardizing on it.
Getting Started with Deep Researcher Agent
The fastest path is to create a project folder, define the experiment in one brief file, and launch the loop with a GPU target. Deep Researcher Agent is intentionally light on setup because the workflow assumes you already know the experiment you want to run.
git clone https://github.com/Xiangyue-Zhang/auto-deep-researcher-24x7.git
cd auto-deep-researcher-24x7
python3.10 -m venv .venv
source .venv/bin/activate
export ANTHROPIC_API_KEY=your_key_here
# or export OPENAI_API_KEY=your_key_here
mkdir -p /path/to/project
cat > /path/to/project/PROJECT_BRIEF.md <<'EOF'
# Goal
Train a ResNet-50 on CIFAR-100 to reach 80%+ accuracy.
# Codebase
Create the training code from scratch in PyTorch.
# What to Try
- Start with a basic ResNet-50 baseline.
- If accuracy < 75%, improve optimization and schedule.
- If accuracy is 75-80%, try augmentation.
- If accuracy > 80%, stop and report.
# Constraints
- Use GPU 0 only
- Max 100 epochs per run
EOF
/auto-experiment --project /path/to/project --gpu 0
After the first run, Deep Researcher Agent should create its workspace artifacts, begin the cycle loop, and emit status notes you can inspect with /experiment-status. If you want richer guidance, open AI_GUIDE.md in Claude, ChatGPT, or Codex and let the assistant help you refine the brief before you burn GPU hours.
Verdict
Deep Researcher Agent is the strongest option for human-in-the-loop deep learning experiment automation when you already have a real training target and need the loop to keep running overnight. Its main strength is structured cycle control; the caveat is that it still depends on good briefs, GPU access, and disciplined oversight. Use it if you care about experiment throughput, not autonomous science theater.