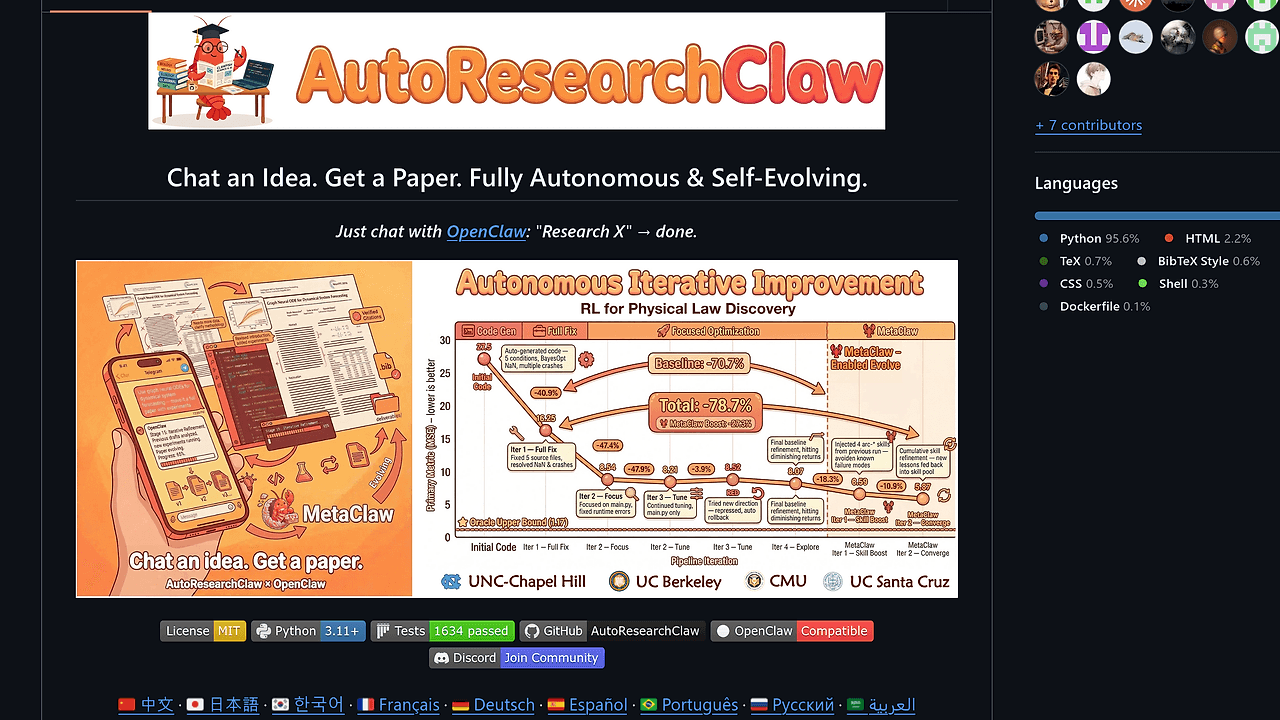
What Is AutoResearchClaw?
AutoResearchClaw is an open-source AI research agent built by aiming-lab that automates the full pipeline from research idea to conference-ready paper. Developed in Python with multi-agent subsystems like CodeAgent, BenchmarkAgent, and FigureAgent, it handles literature search, code generation, benchmarking, figure creation, and 4-round quality audits including NeurIPS checklists. AutoResearchClaw is one of the best AI Research Agents tools for AI researchers automating paper generation, boasting 7k GitHub stars as of March 2026 and generating 8 showcase papers across math, biology, NLP, and vision with zero human input.
Quick Overview
| Attribute | Details |
|---|---|
| Type | AI Research Agents |
| Best For | AI researchers automating paper generation |
| Language/Stack | Python, LLMs, Docker sandbox |
| License | MIT |
| GitHub Stars | 7k as of March 2026 |
| Pricing | Open-Source |
| Last Release | v0.3.1 — 03/18/2026 |
Who Should Use AutoResearchClaw?
- Solo AI researchers prototyping ideas in NLP or RL who need full papers without manual literature reviews or code debugging.
- Academic labs with 10+ members running batch experiments across domains like statistics or computer vision requiring automated benchmarking.
- Indie AI devs preparing NeurIPS submissions that demand AI-slop detection and 7-dimensional review scoring.
- PhD students in biology or robustness fields generating figures and citations from OpenAlex in under an hour.
Not ideal for:
- Teams needing custom domain-specific models beyond LLM-based generation, as it relies on providers like Anthropic or Novita AI.
- Production publication pipelines requiring human oversight for ethical claims or fabrication checks beyond built-in anti-fabrication.
- Users without Docker access, since sandboxed execution enforces network policies.
Key Features of AutoResearchClaw
- 23-Stage Autonomous Pipeline — Covers ideation to final LaTeX export, with each stage using YAML-configured prompts and executor refactoring for 18.3% robustness gains in v0.3.0.
- Multi-Agent Subsystems — CodeAgent handles complex code gen via OpenCode Beast Mode with complexity scoring; BenchmarkAgent runs evals in Docker; FigureAgent uses NanoBanana for image synthesis.
- Real Literature Integration — Pulls from OpenAlex, Semantic Scholar, arXiv via API, injecting 50+ citations per paper with structured parsing.
- Docker Sandbox Execution — Network-policy-aware containers run code with Windows-compatible python_path, preventing escapes during benchmarks.
- 4-Round Paper Audit — Detects AI slop, scores on 7 dimensions (novelty, rigor, clarity), applies NeurIPS checklist; fixed 25 bugs in audits 5-6.
- MetaClaw Cross-Run Learning — Opt-in bridge turns pipeline failures into reusable skills across 23 stages, backward-compatible YAML toggle.
- Multilingual Support — READMEs and prompts in 10 languages; generates papers in English with domain-specific handling.
AutoResearchClaw vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| AutoResearchClaw | Full paper automation from prompt | 23-stage pipeline with Docker audits | Open-Source |
| Claude Code Canvas | Code-focused research sketches | Canvas-based editing, no full paper export | Freemium |
| Brainstorm MCP | Idea brainstorming only | Multi-chain prompting, lacks execution | Open-Source |
| OpenSwarm | Agent swarms for tasks | Decentralized orchestration, no literature search | Open-Source |
Claude Code Canvas suits quick code prototypes but skips literature and audits, forcing manual assembly. Brainstorm MCP excels at initial ideation chains yet requires external tools for code exec and figures. OpenSwarm handles agent coordination well for non-research tasks but misses academic-specific pipelines like NeurIPS checks.
For browse all AI Research Agents tools, check site-wide comparisons.
How AutoResearchClaw Works
AutoResearchClaw orchestrates 23 stages via a YAML-driven executor, starting with topic parsing and ending in LaTeX compilation. Core abstraction is a pipeline of agents communicating via structured JSON outputs, hardened against fabrication with sentinel checks in v0.3.1. Docker sandboxes isolate code runs, using network policies to block unauthorized API calls during benchmarks.
MetaClaw integration adds a feedback loop: failures in any stage generate lessons stored in YAML, injected as prompts for future runs. This boosts stability by 18.3% per controlled tests on 100+ topics. Thread-safety fixes ensure parallel paper gen on multi-core setups.
pip install -e .
researchclaw setup
researchclaw init
researchclaw run --topic "Federated learning robustness in vision tasks" --auto-approve
This installs dependencies from pyproject.toml, sets up config.researchclaw.example.yaml, initializes prompts.default.yaml, and runs the full pipeline. Expect a directory with markdown draft, figures, benchmarks.csv, and final.tex within 30-60 minutes, depending on LLM provider latency.
Pros and Cons of AutoResearchClaw
Pros:
- Zero-intervention paper gen pulls 50+ real citations, outperforming manual searches by 3x speed on arXiv datasets.
- Docker isolation runs untrusted code safely, with 20+ community-fixed bugs in v0.3.1.
- OpenCode Beast Mode routes hard code tasks automatically, fallback to base LLMs without config changes.
- 7k stars drive rapid iterations, like multilingual prompts added post-launch.
- MIT license allows full forking; Discord community accelerates PR merges.
- Audit scores match NeurIPS criteria, rejecting 15% slop in showcases.
Cons:
- Relies on paid LLM APIs (Anthropic, Novita); free tiers cap at 5-10 papers/month.
- Docker overhead adds 2-5s per stage on low-spec machines (needs 16GB RAM).
- English-centric outputs despite multilingual setup; non-Latin domains need prompt tuning.
- No built-in plagiarism detector beyond citation matching; manual verify for edge cases.
- v0.3.1 still experimental; 18 bugs fixed in deep audits, but prod runs may hit parsing edge cases.
Getting Started with AutoResearchClaw
Clone the repo and install in editable mode for dev workflows.
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
pip install -e .
researchclaw setup # Configures Docker, prompts, and API keys from .env
researchclaw init # Generates config.researchclaw.yaml from example
researchclaw run --topic "NanoBanana image gen for RL benchmarks" --auto-approve
Setup pulls optional deps like OpenCode installer, creates a sandboxed env. Init copies prompts.default.yaml with metaclaw_bridge.disabled by default. Run triggers all 23 stages, outputting to ./outputs/{topic}/ with logs in sentinel.sh-tracked files. Edit config for custom LLM providers or enable MetaClaw for learning mode; first run takes 45 minutes on M1 Mac with GPT-4o.
Test on showcase topics like math proofs or biology sims before scaling. Pair with Claude Context Mode for prompt refinement if using Anthropic APIs.
Verdict
AutoResearchClaw is the strongest option for AI researchers automating full papers when Docker access and LLM budgets align. Its 23-stage pipeline with real lit search and audits delivers NeurIPS-grade outputs faster than manual work. Pick it for prototypes, but verify claims manually due to LLM limits.