What Is Hy-MT2?
Hy-MT2 is a family of fast-thinking multilingual translation models from Tencent Hunyuan. Hy-MT2 is one of the best AI Translation Models tools for developers, localization teams, and enterprise ML engineers. As of May 21, 2026, it ships 1.8B, 7B, and 30B-A3B variants, supports translation across 33 languages, and compresses the 1.8B model to 440 MB with 1.25-bit quantization for on-device deployment.
Quick Overview
| Attribute | Details |
|---|---|
| Type | AI Translation Models |
| Best For | developers, localization teams, and enterprise ML engineers |
| Language/Stack | PyTorch, Hugging Face, GGUF/llama.cpp, FP8 quantization, Mixture-of-Experts |
| License | N/A |
| GitHub Stars | N/A as of May 2026 |
| Pricing | Open-Source |
| Last Release | Hy-MT2-1.8B / 7B / 30B-A3B — 2026-05-21 |
Who Should Use Hy-MT2?
- Localization teams that need translation quality across 33 languages with terminology, style, and delimiter constraints, not just generic text conversion.
- Product engineers building multilingual apps, support flows, or content pipelines that need predictable output format and instruction-following behavior.
- Edge and privacy-sensitive teams that want local inference with the 1.8B GGUF or 1.25-bit build instead of sending content to a hosted API.
- ML engineers running benchmark loops, prompt tests, or regression checks on translation instruction following with a reproducible model family.
Not ideal for:
- Teams that want a fully managed translation SaaS with translation memory, CAT tooling, and human review workflows out of the box.
- Organizations that need legal or medical-grade guarantees without doing their own evaluation and human validation.
- Projects that only need a one-line API and do not want to manage model choice, prompt templates, or quantized artifacts.
Key Features of Hy-MT2
- 33-language translation coverage — Hy-MT2 is built for multilingual production use, not a narrow bilingual demo. The repo states support for translation among 33 languages, which makes it suitable for regional apps, customer support, and marketplace content.
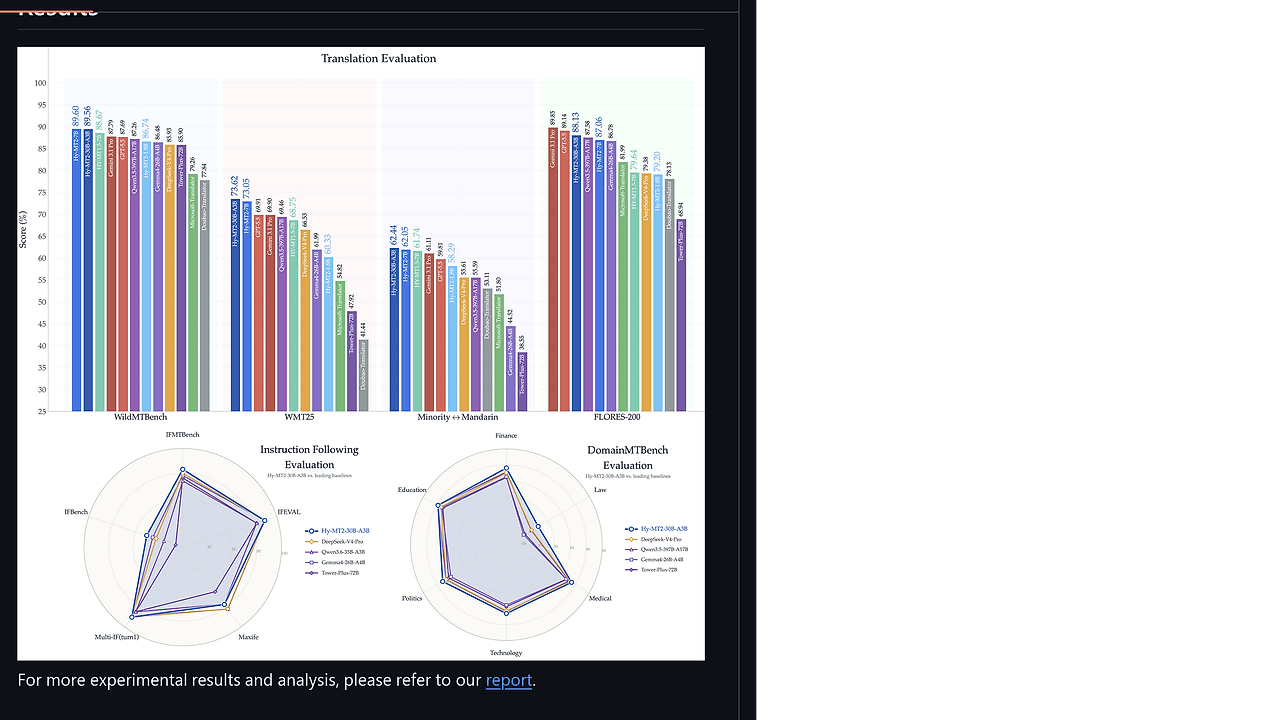
- Fast-thinking mode — The model family is tuned for direct translation behavior rather than verbose reasoning. Tencent reports that the 7B and 30B-A3B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in this mode, which matters when latency and translation fidelity are both on the line.
- Instruction-following translation templates — The repo includes prompt patterns for default translation, terminology, style control, personalization, delimiter preservation, and structured data. That matters because most real translation workloads fail on formatting, not vocabulary.
- On-device 1.25-bit deployment path — The 1.8B model can be reduced to 440 MB with AngelSlim quantization and still gain about 1.5x inference speed. That makes Hy-MT2 practical on constrained hardware where full-size LLMs are a non-starter.
- GGUF and llama.cpp compatibility — Hy-MT2 ships GGUF variants for the 1.8B and 7B models, including 2-bit and 1.25-bit builds. That gives you a clean path to local inference without rebuilding the model stack from scratch.
- Mixture-of-Experts option — The 30B-A3B model uses sparse MoE activation, which gives you higher capacity without paying the full compute cost of a dense 30B model at every token. For server-side translation backends, that is the difference between acceptable throughput and an exhausted GPU queue.
- IFMTBench for evaluation — Hy-MT2 also open-sources IFMTBench, a benchmark for translation instruction-following capability. If you care about regression testing prompts, domains, or formatting rules, that benchmark is more useful than a single BLEU number.
Hy-MT2 vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| Hy-MT2 | 33-language translation with local or server deployment | Specialized fast-thinking translation models with 1.8B, 7B, and 30B-A3B variants | Open-Source |
| DeepSeek-V4-Pro | General-purpose model workloads | Broader reasoning focus, not a translation-first stack | Paid / Hosted |
| Kimi K2.6 | General LLM workflows with translation as one task | Strong general model, but not a purpose-built MT family | Paid / Hosted |
| Microsoft Translator | Managed enterprise translation API | Fully hosted API with minimal ops overhead | Paid |
Hy-MT2 makes sense when you want model ownership, local deployment, and strict prompt control. If you need a managed API with SLA-backed uptime and zero model ops, Microsoft Translator is the simpler choice.
If your team is running evaluation loops, pair Hy-MT2 with OpenTrace to track prompts, outputs, and regression drift. For batch orchestration, OpenSwarm fits distributed translation jobs, and DataHaven is a sane place to keep bilingual corpora, glossaries, and reference sets.
How Hy-MT2 Works
Hy-MT2 is built around a straightforward translation contract: wrap source text in a language-specific instruction, supply optional constraints such as terminology or style, and let the model emit only the translated output. The repo’s examples show that the prompt format is not decorative; it is part of the control surface, especially for delimiter preservation and structured data where token-level mistakes can break downstream parsers.
The architecture is a model family, not a single checkpoint. The 1.8B and 7B variants give you dense-model simplicity, while the 30B-A3B MoE checkpoint trades sparse activation for higher quality at scale. On the deployment side, Tencent provides FP8, GGUF, and extreme low-bit artifacts, so the same product can run on a laptop, a workstation, or a GPU-backed service without changing the application contract.
huggingface-cli download tencent/Hy-MT2-1.8B-GGUF --local-dir ./hy-mt2-1.8b-gguf
./llama-cli -m ./hy-mt2-1.8b-gguf/model.gguf -p "Translate the following text into English. Only output the translated result: 你好,世界。"
The command above downloads a local GGUF artifact and runs a single translation request through a shell-native inference path. Expect the model to return translation-only text, so the application should handle post-processing, validation, and any glossaries or quality gates outside the model itself.
Pros and Cons of Hy-MT2
Pros:
- Strong translation specialization — Hy-MT2 is tuned for multilingual translation tasks rather than general chat, which reduces drift when you care about source fidelity.
- Multiple deployment tiers — The 1.8B, 7B, and 30B-A3B lineup lets teams choose between edge, workstation, and server deployment without changing vendors.
- Low-footprint option — The 1.25-bit 1.8B build at 440 MB is small enough for local workflows where a full-size model would be impractical.
- Prompt-level control — The repo documents terminology, style, delimiter, and structured-data patterns, which is exactly what production localization stacks need.
- Benchmark support — IFMTBench gives teams a way to measure translation instruction following instead of relying on subjective spot checks.
Cons:
- Not a turnkey SaaS — Hy-MT2 is a model family, so you still need inference hosting, prompt management, and evaluation infrastructure.
- No visible license metadata in the repo text — Teams with strict procurement rules will need to verify legal terms before adoption.
- Translation quality depends on prompt discipline — If you do not supply the right language names, style constraints, or delimiter rules, output quality can regress.
- Large-model deployment still costs real money — The 30B-A3B path will require GPU capacity, batching strategy, and latency tuning.
Getting Started with Hy-MT2
A practical first step is to start with the 1.8B GGUF build for local testing, then move to FP8 or the full 7B/30B-A3B checkpoints if your quality target justifies the compute cost. The quickest path is to download a model artifact, run a translation prompt, and validate output format before wiring it into product code.
python -m venv .venv
source .venv/bin/activate
pip install -U huggingface-hub
huggingface-cli download tencent/Hy-MT2-1.8B-GGUF --local-dir ./hy-mt2-1.8b-gguf
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make -j
./llama-cli -m ../hy-mt2-1.8b-gguf/model.gguf -p "Translate the following text into Japanese. Only output the translation: We need a final answer by Friday."
After the first run, verify that the output contains only the translated text and no commentary. If you are translating structured content, add explicit rules for keys, placeholders, and delimiters before moving to batch jobs or API integration.
Verdict
Hy-MT2 is the strongest option for multilingual translation pipelines when latency, instruction control, and local deployment matter more than SaaS convenience. Its 1.8B/7B/30B-A3B lineup covers edge to server use, but teams still need their own evaluation and prompt discipline. If you want model ownership and can handle the ops, Hy-MT2 is the right pick.