What Is Gemma Multimodal Fine-Tuner?
Gemma Multimodal Fine-Tuner is a Python-based multimodal LLM fine-tuning CLI built by Matt Mireles. It is one of the best Multimodal LLM Fine-Tuning tools for Mac ML engineers, indie hackers, and research teams because it trains Gemma LoRA adapters on text, images, and audio while running natively on Apple Silicon, with cloud streaming for datasets that do not fit on disk. The repo targets Gemma 3n and Gemma 4 checkpoints and is designed for local-first training rather than a generic GPU cluster workflow.
The practical distinction is simple: this project is built for people who want to adapt Gemma without renting an H100 or copying terabytes onto a laptop SSD. It keeps the training path narrow, uses PEFT LoRA, and focuses on reproducible CSV-driven data pipelines plus streamed shards from GCS or BigQuery.
Quick Overview
| Attribute | Details |
|---|---|
| Type | Multimodal LLM Fine-Tuning |
| Best For | Mac ML engineers, indie hackers, and research teams |
| Language/Stack | Python 3.10+, PyTorch, Hugging Face Transformers, PEFT LoRA, Apple Silicon MPS, Typer, Rich, Questionary, CSV, GCS, BigQuery |
| License | N/A in scraped text |
| GitHub Stars | N/A as of Feb 2026 |
| Pricing | Open-Source |
| Last Release | N/A — not stated in scraped text |
Who Should Use Gemma Multimodal Fine-Tuner?
- Mac-first ML engineers who want to fine-tune Gemma on an M-series machine without depending on CUDA or a remote workstation.
- Indie hackers shipping private AI products who need local training for customer data, screenshots, call transcripts, or domain-specific assets.
- Research teams working with multimodal data that need captioning, VQA, ASR, or audio-grounded instruction tuning on a repeatable CLI path.
- Data-heavy teams that store training corpora in BigQuery or GCS and want to stream shards instead of staging a full export on a laptop.
Not ideal for:
- Teams that need full fine-tuning of large non-Gemma foundation models, not LoRA on Gemma checkpoints.
- Windows-first or Linux-server-first orgs that have standardized on distributed CUDA training and do not care about Apple Silicon.
- Users who need support for Gemma 26B/31B-class architectures, which this repo explicitly says are not supported by the current audio path.
Key Features of Gemma Multimodal Fine-Tuner
-
Apple Silicon MPS execution — The trainer is wired to bootstrap MPS-related environment variables before Torch loads, which matters on macOS because device selection and memory behavior are decided early. You get a real local training path on M-series hardware instead of a fake "Mac-compatible" wrapper.
-
Text, image, and audio LoRA — The repo supports
modality = text,modality = image, and audio-flavored Gemma workflows on the Gemma-specific finetune path. That makes Gemma Multimodal Fine-Tuner materially different from text-only stacks such as browse all CLI Tools, which typically stop at language data. -
Cloud-streamed datasets — Training data can stream from GCS or BigQuery so you do not need to copy terabytes onto local storage first. This is the right design for large corpora, especially when your raw assets live in warehouse tables or object storage and your laptop is only the control plane.
-
Wizard-driven workflow — The
wizard/layer uses Questionary and Rich to walk through system checks, model selection, dataset selection, and profile generation. The result is a guided CLI with enough structure to be approachable while still producing files the engineer can inspect, edit, and rerun. -
Hierarchical INI configuration — Configuration is layered across defaults, groups, models, datasets, and profiles. That gives Gemma Multimodal Fine-Tuner a deterministic override model, which is better than burying training behavior in shell flags that drift across runs.
-
Gemma-only router — The finetune dispatcher routes only
gemmamodels intogemma_tuner/models/gemma/finetune.py. That narrow scope reduces code-path ambiguity and explains why the repo can support multimodal Gemma training on Mac hardware more consistently than broader fine-tuning stacks. -
Exportable adapter artifacts — Training writes checkpoints and LoRA outputs, then exports a merged Hugging Face / SafeTensors tree. That is useful if you want to ship adapters, do offline evaluation, or move the result into a downstream inference stack.
Gemma Multimodal Fine-Tuner vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| Gemma Multimodal Fine-Tuner | Gemma LoRA on text, image, and audio from a Mac | Apple Silicon-native multimodal path plus streamed cloud datasets | Open-Source |
| MLX-LM | Apple Silicon text workflows | Strong local LLM tooling, but multimodal fine-tuning coverage is narrower | Open-Source |
| Unsloth | Fast single-GPU fine-tuning | Excellent speed on supported CUDA setups, but not Mac-first and not audio-first here | Open-Source |
| axolotl | General-purpose LLM training configs | Flexible distributed training and config breadth, but heavier and more CUDA-oriented | Open-Source |
Pick MLX-LM if your workflow is primarily local text model work on Apple Silicon and you do not need the same image/audio training path. Pick Unsloth if you already have a CUDA box and care more about throughput than Mac-native operation.
Pick axolotl if your team wants a broad training matrix and already standardizes on GPU infrastructure. Pick Gemma Multimodal Fine-Tuner when the constraint is not "most features" but "Gemma multimodal training that works on a Mac without copy-everything-to-disk pain." For adjacent terminal automation workflows, compare browse all CLI Tools and browse all AI Fine-Tuning tools.
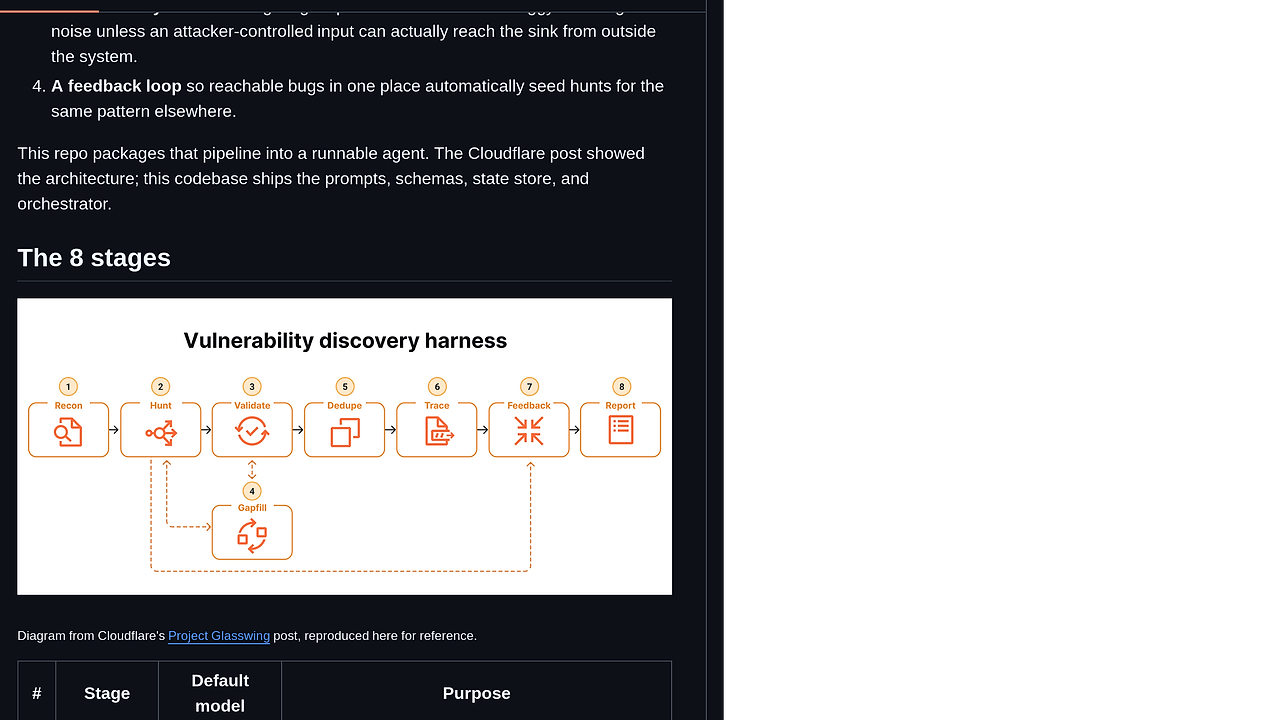
How Gemma Multimodal Fine-Tuner Works
Gemma Multimodal Fine-Tuner uses a Typer-based CLI as the entry point, then bootstraps device settings early so MPS environment variables are in place before Torch initializes. The architecture intentionally stays split into small responsibilities: core/ops.py dispatches operations, scripts/finetune.py routes Gemma jobs, utils/device.py handles MPS/CUDA/CPU selection, and utils/dataset_utils.py handles CSV loading plus protection semantics.
The training path itself is built around Hugging Face Gemma checkpoints with PEFT LoRA on top. That means the base model stays in the Hub-weight format, while the repo trains and exports adapter artifacts, then optionally merges them into a SafeTensors tree for later use. The design choice keeps local training tractable on Apple Silicon, where full model copies are often the wrong trade-off.
# getting started example
brew install [email protected]
python3.12 -m venv .venv
source .venv/bin/activate
pip install -e .
gemma-macos-tuner wizard
gemma-macos-tuner finetune --profile gemma-3n-e2b-it
The wizard command walks through model, dataset, and profile setup, then the finetune command spawns the actual training run from the repo root. Expect a run directory under output/ with metadata, metrics, checkpoints, and LoRA adapter artifacts when training finishes.
Pros and Cons of Gemma Multimodal Fine-Tuner
Pros:
- Runs on Apple Silicon without requiring CUDA, which is the main reason the project exists.
- Supports three modalities — text, image, and audio — under one Gemma-oriented training path.
- Streams from GCS and BigQuery, which avoids local disk bottlenecks for large corpora.
- Clear config hierarchy makes experiments reproducible across datasets, models, and profiles.
- Export path is explicit, so you know where checkpoints and adapter trees live.
- Wizard UI lowers setup friction without hiding the actual CLI commands.
Cons:
- Gemma-only scope limits reuse if your organization trains a mixed-model zoo.
- Large Gemma 26B/31B-class checkpoints are not supported in the current architecture path.
- Image fine-tuning is local CSV only in v1, so some multimodal workflows still need preprocessing.
- macOS arm64 is the happy path, so Rosetta or old Intel Macs are the wrong environment.
- Not a distributed training framework, so teams needing multi-node scaling should look elsewhere.
Getting Started with Gemma Multimodal Fine-Tuner
Start by installing Python 3.10+ on native arm64 macOS, creating a virtual environment, and installing the package in editable mode. Then run the wizard to generate a profile, point it at a local CSV or a streamed cloud source, and launch your first Gemma LoRA job.
brew install [email protected]
python3.12 -m venv .venv
source .venv/bin/activate
pip install -e .
gemma-macos-tuner wizard
After the wizard finishes, you can run a first training job with the generated profile and inspect output/{id}-{profile}/ for metrics and checkpoints. If you are using GCS or BigQuery, configure credentials before launching training so the dataloader can stream shards on demand instead of failing at runtime.
Verdict
Gemma Multimodal Fine-Tuner is the strongest option for local Gemma LoRA training on Apple Silicon when your data spans text, image, or audio and you want to avoid CUDA. Its biggest strength is the narrow, opinionated architecture; its main caveat is the Gemma-only and macOS-first scope. Choose it if you need multimodal training on a Mac, and skip it if you need broad distributed GPU training.