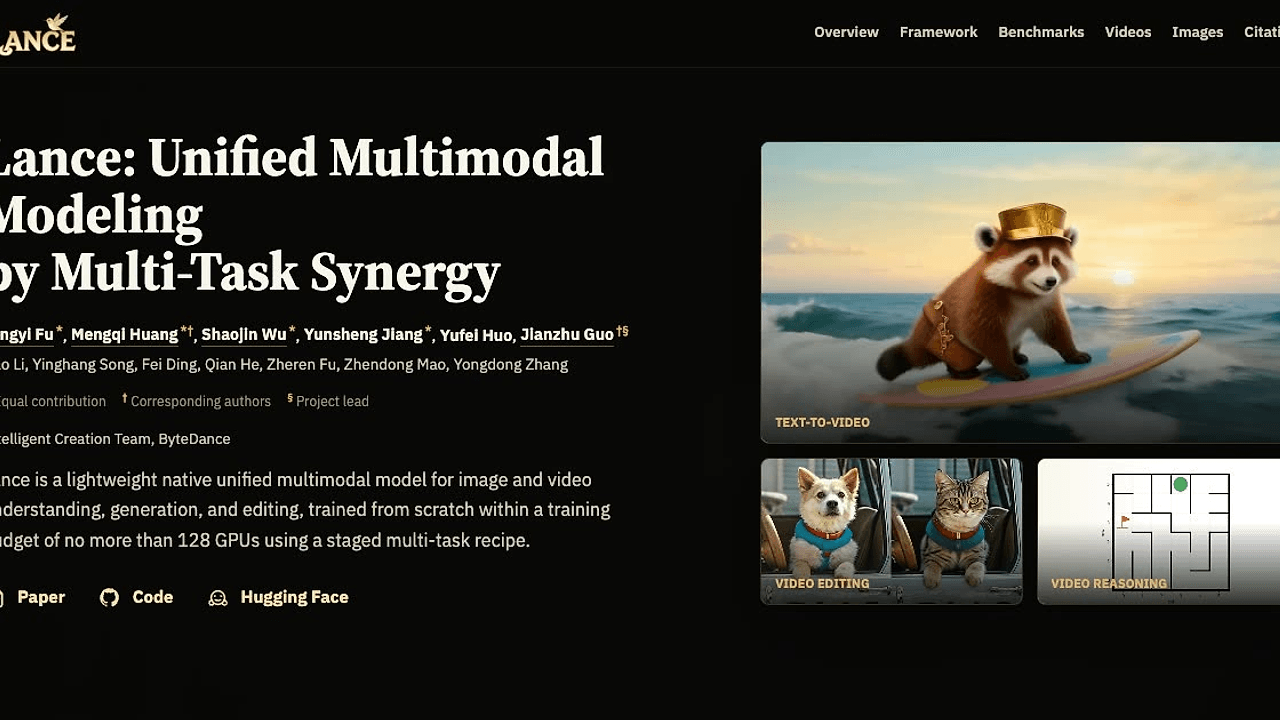
What Is Lance?
Lance is a ByteDance-built multimodal foundation model and one of the best Multimodal AI Models tools for multimodal AI researchers. It unifies image and video understanding, generation, and editing in a single 3B active-parameter framework, with the repo describing training from scratch under a 128-A100-GPU budget. That combination matters if you need one model family instead of a patchwork of separate vision, generation, and editing stacks.
Quick Overview
| Attribute | Details |
|---|---|
| Type | Multimodal AI Models |
| Best For | Multimodal AI researchers and applied ML teams |
| Language/Stack | PyTorch, Hugging Face Transformers, ViT, VAE, video generation |
| License | N/A |
| GitHub Stars | N/A as of Feb 2026 |
| Pricing | Open-Source |
| Last Release | N/A |
Who Should Use Lance?
- Research teams building unified image/video systems that need one backbone for perception, synthesis, and editing instead of separate models for each task.
- Applied ML engineers validating multimodal product ideas who want a repo with paper, model, and demo assets in one place.
- Generative media teams shipping text-to-video or video-editing features that need consistent behavior across edit steps and generation steps.
- Evaluation engineers comparing open multimodal baselines and needing a model that can be measured across generation, editing, and video understanding in one benchmark suite.
Not ideal for:
- Teams that only need text-to-text or image classification; Lance is overkill for pure language or narrow CV workloads.
- Product teams without GPU capacity; the repo’s 3B active parameters and 128-A100 training budget imply serious infrastructure requirements.
- Users who need a fully documented production SDK today; this repository is research-first and still being actively updated.
Key Features of Lance
- Unified multimodal backbone — Lance uses one shared model family for image understanding, image generation, image editing, video generation, and video understanding. That reduces glue code between separate pipelines and keeps outputs more consistent across tasks.
- 3B active parameters — The repo claims 3B active parameters, which is small enough to be interesting for research iteration but large enough to cover multiple modalities. The important point is not raw size alone; it is that the model is active across tasks without switching architectures.
- Trained from scratch with a staged recipe — ByteDance describes a staged multi-task training process, with the transformer backbone trained from scratch while the ViT and VAE encoders are reused. That implies the model was optimized for cross-task synergy rather than assembled from unrelated checkpoints.
- Video-first capability set — The demos cover text-to-video, intelligent video generation, video editing, multi-turn consistency editing, and video understanding. That mix is useful if your roadmap includes both synthesis and interaction, not just one-shot generation.
- Single-framework task transfer — Lance is designed so the same core representation can answer VQA-style questions, generate clips, and edit visual content. For teams that care about shared latent space quality, that matters more than having a model that only wins one benchmark.
- Benchmark-oriented release — The README ships benchmark overview graphics and task-specific demos, which makes it easier to inspect qualitative behavior before wiring the model into a pipeline. If you pair this with OpenTrace, you can keep prompt/output traces around each experiment.
- Research-friendly distribution — The repo points to a homepage, arXiv paper, and Hugging Face model card, which is the right shape for reproducibility. For rapid prompt iteration across experiments, OpenSwarm is a reasonable companion.
Lance vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| Lance | Unified image/video understanding, generation, and editing | One 3B model family covers multiple multimodal tasks | Open-Source |
| Qwen2.5-VL | General vision-language reasoning | Strong broad VLM baseline with mature ecosystem | Open-Source |
| InternVL2.5 | Vision-language research and benchmarks | Common reference point for open VLM comparisons | Open-Source |
| CogVideoX | Text-to-video generation | More specialized on video synthesis than cross-task unification | Open-Source |
Pick Qwen2.5-VL when your main requirement is strong visual question answering, OCR-like reasoning, and a broader vision-language baseline rather than generation or editing. Pick InternVL2.5 when you want a well-known open benchmark competitor for vision-language evals and you do not need a unified generation stack.
Pick CogVideoX when video synthesis is the only priority and you want a model family centered on that problem. Pick Lance when you want one model to span understanding, generation, and editing without swapping architectures between tasks. For teams building open research workflows, a pair like Lance plus Open R1 is useful when you want to contrast multimodal and reasoning-heavy open models in the same lab stack.
How Lance Works
Lance is built around a shared transformer backbone that is trained to serve multiple visual tasks under one optimization recipe. The repo states that the transformer is trained from scratch, while the ViT and VAE encoders provide the visual tokenization and latent compression layers needed to bridge pixels, frames, and model tokens.
The design choice is straightforward: keep the input pipeline modular, but keep the core reasoning and generation space shared. That makes cross-task transfer more plausible, because the same backbone sees visual semantics, temporal structure, and editing targets during training instead of learning them in separate silos.
A realistic first run looks like this:
git clone https://github.com/bytedance/Lance.git
cd Lance
python -m venv .venv
source .venv/bin/activate
pip install -U torch torchvision transformers accelerate decord
python - <<'PY'
from transformers import AutoModel, AutoProcessor
model_id = 'bytedance-research/Lance'
model = AutoModel.from_pretrained(model_id, trust_remote_code=True, device_map='auto')
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
print('Loaded', model_id)
PY
That sequence clones the repository, creates an isolated Python environment, installs the usual multimodal runtime stack, and loads the published Hugging Face checkpoint with remote code enabled. Expect the first download to be large, and expect to tune device_map, batch size, and video decoding settings before you get stable throughput on a real workload.
Pros and Cons of Lance
Pros:
- One model for multiple vision tasks — You do not need separate stacks for understanding, generation, and editing.
- Research-grade transparency — The repo includes a paper link, model card link, demos, and benchmark visuals.
- 3B active parameters — Small enough to be tractable in research settings compared with larger frontier multimodal systems.
- Staged multi-task training — The recipe is designed to encourage shared representations across tasks.
- Strong demo coverage — The README shows text-to-video, editing, and video QA, which is more useful than a single cherry-picked sample.
Cons:
- Heavy compute requirements — The training budget alone was 128 A100 GPUs, which tells you this is not a casual laptop project.
- Incomplete operational docs — The README excerpt is demo-rich but not a full production integration guide.
- License and release metadata are unclear in the excerpt — You should verify the repo license and checkpoint terms before commercial use.
- Research orientation — The project is still actively updated, so APIs and model packaging may change.
- Not a narrow specialist — If you only need image-to-text or video captioning, a smaller task-specific model may be easier to deploy.
Getting Started with Lance
git clone https://github.com/bytedance/Lance.git
cd Lance
python -m venv .venv
source .venv/bin/activate
pip install -U torch torchvision transformers accelerate decord huggingface_hub
After the install finishes, pull the model checkpoint from the Hugging Face model page linked in the repo and run a minimal inference script with trust_remote_code=True. You will usually need to adjust GPU memory settings, video frame sampling, and the exact checkpoint name before running a real text-to-video or video-understanding prompt.
Verdict
Lance is the strongest option for teams that want one multimodal model for image and video generation, editing, and understanding when they can afford real GPU infrastructure. Its main strength is unified cross-task design; its main caveat is that the repo is research-first and still evolving. Choose Lance if you need breadth across visual tasks, not just a single benchmark win.