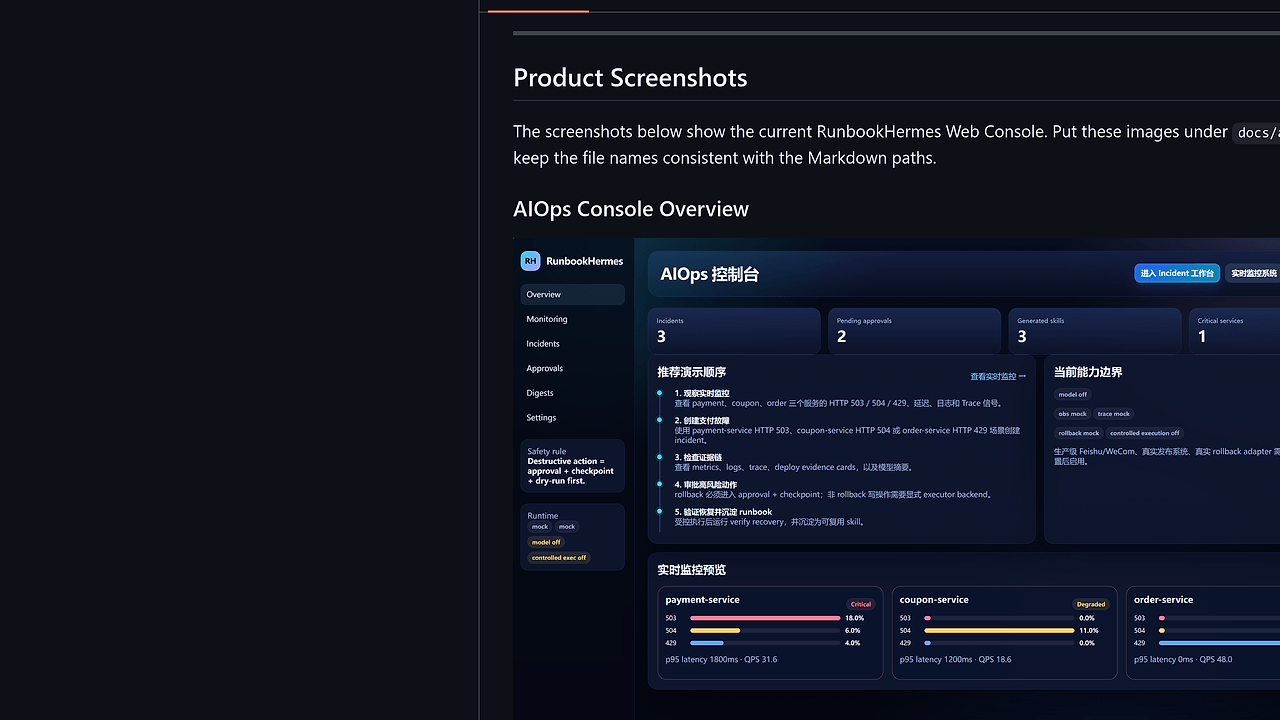
What Is RunbookHermes?
RunbookHermes is a Hermes-native AIOps incident-response agent built by Tommy-yw on top of the official Hermes Agent runtime, and it is one of the best AIOps Automation tools for SREs and payment platform teams. It turns metrics, logs, traces, approvals, rollback, and runbook learning into a single workflow, and the repo documents 11 console and incident-detail screens covering intake, evidence, remediation, and knowledge capture.
Quick Overview
| Attribute | Details |
|---|---|
| Type | AIOps Automation |
| Best For | SREs, platform engineers, and payment incident teams |
| Language/Stack | Hermes Agent runtime with Prometheus, Loki, Jaeger, Alertmanager, Feishu, WeCom, and Web/API integrations |
| License | N/A in scraped text |
| GitHub Stars | N/A as of Feb 2026 |
| Pricing | Open-Source |
| Last Release | N/A |
Who Should Use RunbookHermes?
- Payment-platform SREs handling checkout, settlement, or auth outages who need evidence-backed triage instead of guesswork.
- Platform teams running Prometheus, Loki, Jaeger, Alertmanager, Feishu, or WeCom and wanting one incident workflow rather than a pile of disconnected scripts.
- Incident commanders who need approval-gated remediation, checkpointing, rollback, and recovery verification before touching production.
- Runbook owners who want recurring fixes to become reusable skills rather than buried notes in a postmortem doc.
Not ideal for:
- Teams without structured observability data, because RunbookHermes is designed to reason from metrics, logs, traces, and deployment state.
- Teams looking for a generic chatbot or ticket summarizer, because the product is built around incident execution and safety gates.
- Small services that only need a basic alert bot, since the setup cost is higher than a simple webhook relay.
Key Features of RunbookHermes
- Multi-channel incident intake — RunbookHermes accepts incidents from Web, Alertmanager, Feishu, WeCom, Hermes profile entry, and API endpoints. That gives ops teams one normalized path regardless of where the signal starts.
- EvidenceStack context engine — The agent compresses alert noise into structured evidence, hypotheses, actions, and final answers. That is the right shape for root-cause analysis because it keeps the model anchored to observed state instead of raw logs.
- Approval Center — Risky actions are not executed by default. Operators review the action, risk level, checkpoint, and payload before the system moves forward.
- Checkpoint and rollback flow — RunbookHermes places write or destructive actions behind dry-run, controlled execution, and recovery verification. This is a hard safety boundary, not a cosmetic confirmation dialog.
- IncidentMemory — The memory layer stores service profiles, incident summaries, team preferences, and a skill index. That lets the system remember operational context without stuffing every prior incident into the prompt.
- Runbook skill generation — After an incident is processed, RunbookHermes can turn the response path into a reusable skill. In practice, that means a payment HTTP 503 triage can become a repeatable playbook instead of a one-off fix.
- Integration readiness view — The settings page exposes whether model, observability, execution, Feishu, WeCom, and other production interfaces are configured. That is useful because it makes missing dependencies visible before the first real incident.
RunbookHermes vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| RunbookHermes | Payment incident response and evidence-driven remediation | Hermes-native agent with approval gates, checkpoints, and runbook learning | Open-Source |
| OpenSwarm | General multi-agent orchestration | Broader agent coordination, less incident-specific safety and evidence handling | Open-Source |
| djevops | DevOps workflow automation | Better fit for deployment automation than incident memory and RCA | Open-Source |
| OpenTrace | Trace-first debugging | Strong when the core problem is distributed tracing rather than remediation workflows | Open-Source |
Pick OpenSwarm if you want general agent orchestration across many tasks and do not need a dedicated incident control plane. Pick djevops when the main problem is deployment automation rather than evidence collection and approval gating. Pick OpenTrace when tracing is the bottleneck and you want a narrower diagnosis surface before bringing in an execution agent.
How RunbookHermes Works
RunbookHermes starts by normalizing every signal into the same incident command, whether the source is Alertmanager, Feishu, WeCom, Web, or API. Hermes provides the agent runtime, provider routing, tool invocation, memory hooks, and safety boundaries, while RunbookHermes adds the incident domain model on top. The core abstractions are EvidenceStack for ordered evidence, IncidentMemory for durable context, and generated skills for repeatable fixes.
The design is intentionally opinionated about where state lives. Evidence is kept structured so the model reasons over metrics, logs, traces, deployment state, and action history rather than unbounded text blobs. That is why the root-cause tab separates deterministic evidence from optional model-assisted explanation, and why the model summary is only enabled when a provider is configured.
Safety is enforced before anything can change production state. Approval, checkpoint, dry-run, controlled execution, and recovery verification sit between diagnosis and action, which means RunbookHermes can recommend a rollback without blindly applying it. For payment systems, that matters because a bad remediation can cause a second outage faster than a human can recover.
curl -X POST http://localhost:8080/api/incidents -H 'Content-Type: application/json' -d @sample-incident.json
That request creates a normalized incident record from an external signal. RunbookHermes then enriches it with evidence from observability systems, builds a timeline, and pauses for approval before any risky action is executed. If the remediation succeeds, the system can fold the incident back into a reusable runbook skill.
Pros and Cons of RunbookHermes
Pros:
- Evidence-first triage reduces dependence on model guesses and keeps incident handling tied to observed system state.
- Multi-channel ingestion lets the same incident pipeline handle Web, Alertmanager, Feishu, WeCom, and API entry points.
- Approval gating and checkpointing lower the blast radius of destructive remediation.
- IncidentMemory keeps service-specific knowledge available without forcing every prior incident into the prompt.
- Runbook skill generation turns successful fixes into operational assets instead of leaving them in a postmortem.
- The integration status page makes missing model, observability, or execution wiring obvious before production use.
Cons:
- The setup burden is higher than a simple alert bot because the system expects observability backends and execution adapters.
- RunbookHermes is a bad fit for teams without clean metrics, logs, and traces, since the workflow depends on evidence quality.
- Fully autonomous remediation is not the point here, so teams wanting zero-touch action will find the approval gates restrictive.
- The model-assisted summary path is optional, which means the most useful output still depends on external model provider configuration.
- It is specialized for incident response, so it is not the right choice if you only need generic agent orchestration.
Getting Started with RunbookHermes
git clone https://github.com/Tommy-yw/RunbookHermes.git
cd RunbookHermes
cp .env.example .env
export PROMETHEUS_URL=http://localhost:9090
export LOKI_URL=http://localhost:3100
export JAEGER_URL=http://localhost:16686
docker compose up --build
After startup, open the Web Console and check the integration readiness page to confirm that observability and execution endpoints are wired correctly. Configure model provider credentials only if you want model-assisted summaries; the evidence-driven workflow still works without that layer. Send a test incident from Alertmanager or the API and verify that approval, checkpoint, and recovery verification are triggered in the expected order.
Verdict
RunbookHermes is the strongest option for payment incident response when you already have Prometheus, Loki, or Jaeger data and need human-approved remediation. Its biggest strength is the evidence-first workflow; its main caveat is setup complexity. Choose RunbookHermes if you want incident handling to generate reusable operational knowledge, not just another alert thread.