What Is TurboQuant+?
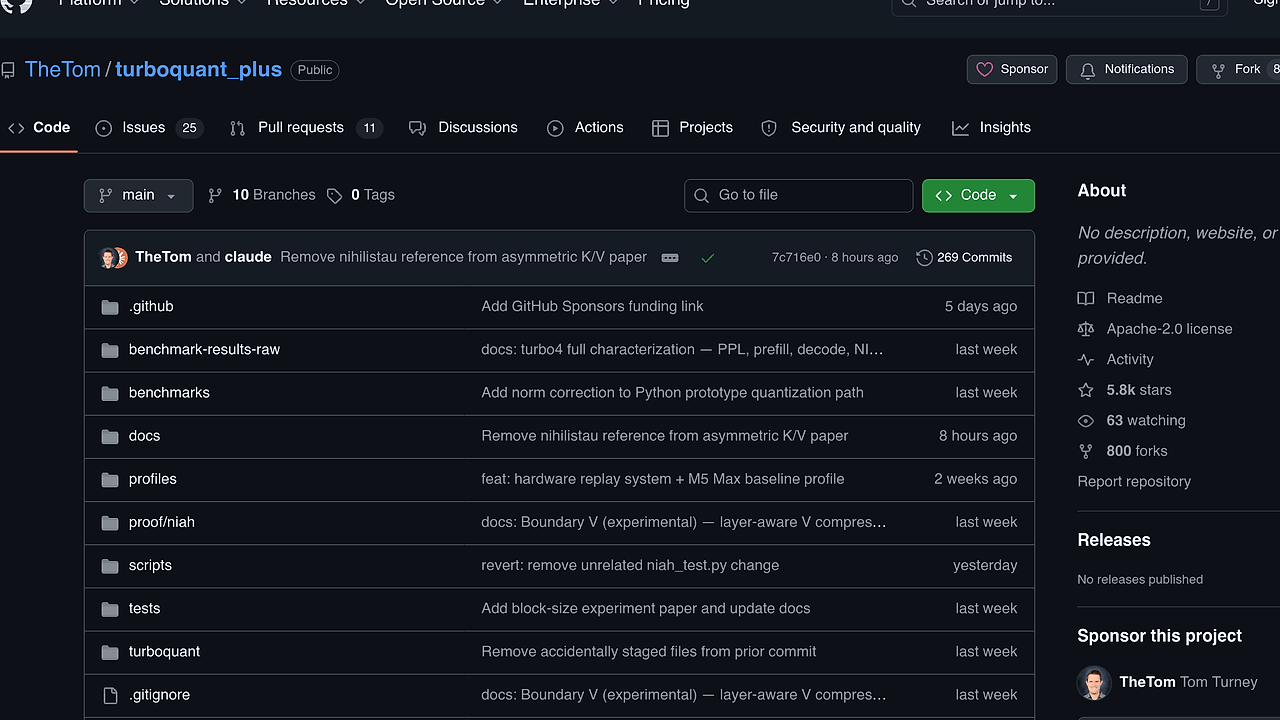
TurboQuant+ is a llama.cpp research fork from TheTom that implements KV cache compression for local LLM inference, and it is one of the best LLM Inference Optimization tools for local LLM engineers, benchmarkers, and llama.cpp contributors. The repository has 5.8k stars as of Feb 2026 and reports 3.8-6.4x cache compression with PolarQuant plus Walsh-Hadamard rotation, making it a serious benchmark target rather than a toy prototype.
The project exists to test ideas, collect reproducible quality data, and compare backend behavior across Metal and CUDA. It is not positioned as a permanent fork; it is a research workspace where stable pieces can be upstreamed in smaller patches after validation.
Quick Overview
| Attribute | Details |
|---|---|
| Type | LLM Inference Optimization |
| Best For | local LLM engineers, llama.cpp contributors, and benchmarking teams |
| Language/Stack | C++ llama.cpp fork with Python benchmark scripts and GGUF-focused experiments |
| License | Apache 2.0 |
| GitHub Stars | 5.8k as of Feb 2026 |
| Pricing | Open-Source |
| Last Release | N/A — active research branch |
Who Should Use TurboQuant+?
- llama.cpp contributors who need reproducible evidence before landing KV-cache changes into upstream code.
- Inference engineers running long-context workloads where cache memory, decode throughput, and quality all matter at the same time.
- Benchmarking teams comparing Metal, CUDA, and mixed backends on the same model family and context window.
- Indie hackers shipping local assistants on Apple Silicon who want better context depth without jumping to larger VRAM tiers.
Not ideal for:
- Teams that want a stable, production-hardened library with a frozen API surface.
- Users who only need a single prebuilt binary and do not care about experimental flags, backend-specific profiles, or benchmark artifacts.
- Projects that do not use llama.cpp, GGUF models, or local inference workflows.
Key Features of TurboQuant+
- Asymmetric K/V compression — TurboQuant+ separates key and value precision so the system can keep keys at higher fidelity while pushing values much lower. The branch’s core finding is that quality loss comes from K compression, not V compression, which is why asymmetric settings like
q8_0-K + turbo-Vrecover models that fail under symmetric quantization. - V compression can go extremely low — the repo documents that compressing the value cache down to 2 bits has shown no measurable attention-quality drop when key precision is preserved. That matters because it reframes the bottleneck: you are not paying for V bits, you are paying for reckless key quantization.
- Boundary-layer protection — TurboQuant+ shows that the first 2 + last 2 layers are disproportionately sensitive. Protecting those layers at higher precision reportedly recovers 37-91% of the quality gap, which is the kind of result that changes how you design a mixed-precision inference policy.
- PolarQuant + Walsh-Hadamard rotation — the branch uses a rotation-based scheme to squeeze KV cache size while maintaining usable decode quality. The reported compression range of 3.8-6.4x is large enough to change the feasibility of long-context runs on consumer hardware.
- Backend validation across Metal and CUDA — the findings were independently validated on Apple Silicon M5 Max, RTX 4090, and RTX 3090. That cross-backend confirmation matters because many quantization claims collapse when moved off a single reference GPU.
- Benchmark and quality artifacts — the repository includes
benchmark-results-raw/,benchmarks/,profiles/, andproof/niah/, so you can inspect timing, perplexity, NIAH-style retrieval behavior, and hardware replay data instead of trusting a README claim. - Follow-on experiments — the branch includes sparse V dequant, block-size optimization, and turbo4 resurrection work. That makes TurboQuant+ more useful as a research base than as a single-purpose patch set.
TurboQuant+ vs Alternatives
| Tool | Best For | Key Differentiator | Pricing |
|---|---|---|---|
| TurboQuant+ | KV-cache compression research for llama.cpp | Separates K and V precision, with published backend benchmarks and quality findings | Open-Source |
| llama.cpp | General local LLM inference | Stable upstream project with broad model support and a larger user base | Open-Source |
| OpenTrace | Profiling and trace analysis around model runs | Better for measuring runtime behavior than for changing quantization strategy | Open-Source |
| DataHaven | Storing and comparing benchmark artifacts | Better for dataset and result management than for inference implementation | Open-Source |
Pick llama.cpp when you want the mainstream runtime and you do not need experimental cache-compression work. Pick OpenTrace when your bottleneck is observability and timing attribution rather than the quantization algorithm itself. Pick DataHaven when the real problem is keeping benchmark runs, raw logs, and artifacts organized across machines.
How TurboQuant+ Works
TurboQuant+ treats the KV cache as a separate optimization surface instead of a monolithic blob. The design idea is simple: preserve the attention signal that matters most, compress the parts that can absorb error, and validate every change against perplexity, NIAH-style retrieval, and decode timing.
The branch’s main technical bet is asymmetric precision. Keys are kept at a higher precision tier because quality degradation is dominated by K compression, while values can be compressed far more aggressively with little or no measurable impact on attention quality. That is why the repo emphasizes q8_0-K + turbo-V style configurations and boundary-layer exceptions instead of symmetric cache quantization.
git clone https://github.com/TheTom/turboquant_plus.git
cd turboquant_plus
python -m venv .venv
source .venv/bin/activate
pip install -e .
pytest -q
The command sequence above clones the research workspace, creates an isolated Python environment, installs the repo in editable mode, and runs the test suite. On a real setup, you would follow that with the repository’s benchmark or profiling entrypoints, then compare your results against the raw artifacts in benchmark-results-raw/ and profiles/.
A practical way to use TurboQuant+ is to pair it with OpenTrace when you need trace-level timing around prefill and decode. If you are collecting outputs across multiple models, backends, and context windows, DataHaven is a sensible place to stash the raw artifacts and compare runs without losing provenance.
Pros and Cons of TurboQuant+
Pros:
- Strong empirical framing — the repo does not just claim compression; it ties results to quality metrics, backend validation, and model-family coverage.
- Clear failure analysis — TurboQuant+ identifies K compression as the main quality risk, which makes optimization decisions easier than guessing at mixed-precision policy.
- Long-context relevance — the reported compression gains matter most where KV memory becomes the limiting factor, especially on consumer GPUs and unified-memory Macs.
- Cross-backend evidence — confirmations on Metal and CUDA reduce the chance that the result is a one-off artifact of a single runtime.
- Research-friendly structure — separate benchmark, proof, and profile directories make it easier to reproduce and audit claims.
Cons:
- Experimental by design — this is not a stable API package, so teams should expect refactors and partial upstreaming rather than semantic-version guarantees.
- Upstream dependency — the value of TurboQuant+ is tied to llama.cpp internals, which means changes in upstream can break or invalidate local patches.
- Benchmark burden — you need disciplined evaluation across models, contexts, and hardware; casual testing will miss the edge cases this project is meant to expose.
- Hardware-specific tuning — the best configuration can differ between Metal and CUDA, so a single “best setting” is a bad assumption.
- Not a full inference stack — TurboQuant+ optimizes a slice of the pipeline, not the entire deployment story.
Getting Started with TurboQuant+
The fastest way to start with TurboQuant+ is to clone the repo, install the local Python environment, and run the included validation tests before touching any benchmarks. That gives you a clean baseline for the fork’s package layout and protects you from comparing results against a broken checkout.
git clone https://github.com/TheTom/turboquant_plus.git
cd turboquant_plus
python -m venv .venv
source .venv/bin/activate
pip install -e .
python -m pip install -U pytest
pytest -q
After that, inspect benchmarks/, profiles/, and benchmark-results-raw/ to find the repo’s current experiment entrypoints and expected output formats. You will usually need a local llama.cpp-compatible model file in GGUF format and enough RAM or VRAM to compare baseline versus compressed-cache runs under the same prompt and context settings.
Verdict
TurboQuant+ is the strongest option for evaluating KV-cache compression in llama.cpp when you care about reproducible quality metrics across backends. Its main strength is the asymmetric K/V analysis that explains why some quantization schemes hold up and others do not. The caveat is that it is still a research branch, so expect churn. Use it when you want evidence, not slogans.